
欢迎来到 protocol buffers 的开发者指南。protocol buffers 是一个语言中立,平台中立针对通讯协议,数据存储和其他领域中对结构化数据进行序列化的扩展方法。 本文档主要针对的是 Java,C++ 或 Python 的开发人员希望在开发的应用程序中使用 Protocol Buffers。这个有关 Protocol Buffers 摘要性的介绍将会告诉你如何开始使用 Protocol Buffers。 如果你希望更加深入的了解有关 Protocol Buffers 的内容,你可以进入 tutorials 或者 protocol buffer encoding 页面来详细了解。 有关 API 的参考文档,请参考页面:reference documentation 这里提供了所有这 3 种语言的参考,同时也针对 .proto language 和 style 提供相关的指南。 什么是 Protocol Buffers Protocol buffers 是对结构化数据序列化的一个灵活,高效,自动化工具 —— 你可以将 Protocol buffers 想象成 XML,但是体积更小,更快也更加简单。 你可以自己定义你的结构化数据,然后你可以使用特定的代码生成工具来非常容易对你的结构化数据进行读取和写入。这些数据的读取和写入可以是一系列的数据流和使用不同的计算机程序语言。 你甚至可以在不对已经部署的程序进行破坏的情况下更新你的数据结构。 Protocol Buffers 是如何进行工作的 你需要制定你希望如何将你的数据进行序列化。你是通过 proto 文件来定义你的消息结构化数据的。 每一 protocol buffer message 是一个小的信息记录逻辑,这个消息中包含有一系列的名字,变量对照序列。 下面是一些基本的.proto 文件,这些文件中定义了一个消息,这个消息包含有一个 person 信息: message Person { required string name = 1; required int32 id = 2; optional string email = 3; enum PhoneType { MOBILE = 0; HOME = 1; WORK = 2; } message PhoneNumber { required string number = 1; optional PhoneType type = 2 [default = HOME]; } repeated PhoneNumber phone = 4; } 通过上面你可以看到这个消息的格式非常简单—— 每一个消息类型都有一个或者多个唯一进行编号的字段,每一个字段包含有一个名字和变量类型。 变量可以为数字(整形或者浮点型)(numbers),布尔类型(booleans),字符串(strings),原生二进制(raw bytes)甚至其他的 protocol buffer 消息类型,能够允许你分级的结构化你的数据。 你可以将字段指定为可选字段(optional fields),必须字段(required fields)和重复字段(repeated fields)。你可以从下面的 Protocol Buffer Language Guide 页面中找到更多有关 .proto 的定义。 一旦你成功定义了你的消息,你可以针对你使用的语言使用你定义的 .proto 来运行 protocol buffer 编译器(protocol buffer compiler)来生成数据访问类。 针对每一个字段,在数据访问类中提供了简单的访问方法(例如 name() 和 set_name())和序列化到原生 2 进制数据和从原生 2 进制数据反序列化的方法。 针对上面的定义,如果你现在使用的是 C++ 语言的话,当你把消息定义进行编译后,你将会得到一个称为 Person 的类。对数据进行序列化和从序列化的数据中(protocol buffer 消息)重新获得 Person 数据。 然后你可以写一些类似 Person person; 的代码。 Person person; person.set_name("John Doe"); person.set_id(1234); person.set_email("jdoe@example.com"); fstream output("myfile", ios::out | ios::binary); person.SerializeToOstream(&output); 随后,你可以对消息进行读取: fstream input("myfile", ios::in | ios::binary); Person person; person.ParseFromIstream(&input); cout << "Name: " << person.name() << endl; cout << "E-mail: " << person.email() << endl; 你可以向你的消息中添加新的字段而不会损坏老的消息。这是因为在老的消息处理中,针对新的字段是完全忽略掉的。因此,如果你在你的通讯协议中使用 protocol buffers 为数据结构的话, 你可以对你的协议和消息进行扩展而不需要担心老的代码没有办法编译通过,或者损坏老的代码。 你可以访问 API Reference section 页面中的内容来了解完整 protocol buffer 代码的生成和使用。 你也可以在 Protocol Buffer Encoding 页面中了解更多protocol buffer 消息是如何进行编码的。 为什么不使用 XML 针对 XML 来说 Protocol Buffers 具有更多的优势来对序列化结构数据。 更加简单 小于 XML 3 到 10 倍 快于 XML 20 到 100 倍 松耦合 使用程序工具来创建数据访问类,使数访问类更加简单 假设,你需要讲 person 这个数据进行定义,在 XML 你需要使用: <person> <name>John Doe</name>…

如何能在 MariaDB 数据库中显示数据库表: +--------------+--------------------+----------------------------+------------------------+----------+ | CATALOG_NAME | SCHEMA_NAME | DEFAULT_CHARACTER_SET_NAME | DEFAULT_COLLATION_NAME | SQL_PATH | +--------------+--------------------+----------------------------+------------------------+----------+ | def | information_schema | utf8 | utf8_general_ci | NULL | | def | mysql | latin1 | latin1_swedish_ci | NULL | | def | ossez_bbs | utf8 | utf8_general_ci | NULL | | def | ossez_ucenter | utf8 | utf8_general_ci | NULL | | def | performance_schema | utf8 | utf8_general_ci | NULL | | def | test | latin1 | latin1_swedish_ci | NULL | +--------------+--------------------+----------------------------+------------------------+----------+ 可以使用下面的 SQL 来进行查看即可。 SELECT * FROM INFORMATION_SCHEMA.SCHEMATA; 上图显示的是执行结果。 https://www.ossez.com/t/mariadb/741
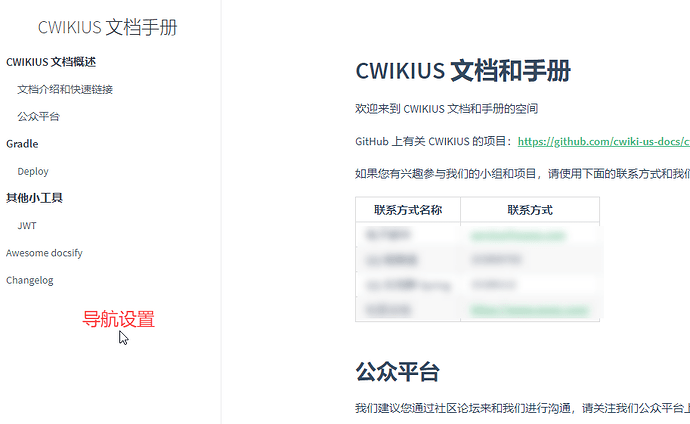
如下图中的文档中的 docsify 边栏是如何设置的? 配置方法 在你的项目的 index.html 文件中,添加参数: loadSidebar: true 然后再在项目中添加一个 _sidebar.md 文件,这个文件的格式为: - CWIKIUS 文档概述 - [文档介绍和快速链接](README.md) - [公众平台](CONTACT.md) - Gradle - [Deploy](deploy.md) - 其他小工具 - [JWT](jwt/README.md) - [Awesome docsify](awesome.md) - [Changelog](changelog.md) 采用分级的方式链接到你的项目文档路径中。 然后保存提交就可以了。 https://www.ossez.com/t/docsify/740
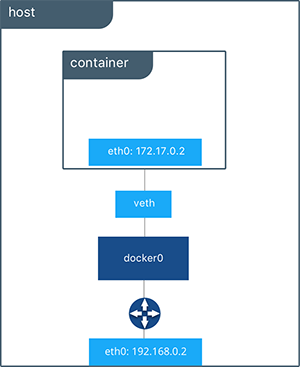
如果你通过 Docker 提供的用户指南,你应该已经完成了构建你的第一个 Docker 容器,并且运行了示例应用。 你已经构建了你自己的镜像(images)。本部分的内容将会指导你如何对你的容器进行网络配置。 使用默认网络来运行一个容器 Docker 能够支持通过 network drivers 来使用网络的容器。在默认的情况下,Docker 为你提供了 2 个网络驱动: bridge 和 overlay 驱动。 你也可以通过写一个网络驱动插件来创建你自己的网络驱动,但是这个属于比较高级的任务了。 在任何完成安装的 Docker 中将会自动包含有下面 3 个网络驱动,你可以通过下面的命令来列表出来: $ docker network ls NETWORK ID NAME DRIVER 18a2866682b8 none null c288470c46f6 host host 7b369448dccb bridge bridge 被命名 bridge 的网络是一个特殊的网络。除非你在运行的时候指定一个网络,否则 Docker 容器将会一直运行这个网络。尝试运行下面的命令: $ docker run -itd --name=networktest ubuntu 74695c9cea6d9810718fddadc01a727a5dd3ce6a69d09752239736c030599741 通过检查网络,可以非常容易的找到你容器的 IP 地址。 $ docker network inspect bridge [ { "Name": "bridge", "Id": "f7ab26d71dbd6f557852c7156ae0574bbf62c42f539b50c8ebde0f728a253b6f", "Scope": "local", "Driver": "bridge", "EnableIPv6": false, "IPAM": { "Driver": "default", "Options": null, "Config": [ { "Subnet": "172.17.0.1/16", "Gateway": "172.17.0.1" } ] }, "Internal": false, "Containers": { "3386a527aa08b37ea9232cbcace2d2458d49f44bb05a6b775fba7ddd40d8f92c": { "Name": "networktest", "EndpointID": "647c12443e91faf0fd508b6edfe59c30b642abb60dfab890b4bdccee38750bc1", "MacAddress": "02:42:ac:11:00:02", "IPv4Address": "172.17.0.2/16", "IPv6Address": "" } }, "Options": { "com.docker.network.bridge.default_bridge": "true", "com.docker.network.bridge.enable_icc": "true", "com.docker.network.bridge.enable_ip_masquerade": "true", "com.docker.network.bridge.host_binding_ipv4": "0.0.0.0", "com.docker.network.bridge.name": "docker0", "com.docker.network.driver.mtu": "9001" }, "Labels": {} } ] 通过断开与容器的链接,你也可以将容器从网络中删除。 如果要将容器从网络中删除的话,你需要同时提供网络名(network name)和容器名(container name)。 你也可以使用容器 ID,但是使用容器名相对使用容器 ID 来说,更加快速。 $ docker network disconnect bridge networktest 尽管你可以将容器从一个网络中断开连接,但是你不能删除 Docker 内部构建的被命名为 bridge 的 bridge 网络。 网络是将一个容器与其他容器独立开或者容器与其他网络独立开的最常规的方式。 因此,当你有更多使用 Docker 经验的时候,可以尝试创建你自己的网络。 https://www.ossez.com/t/docker/739
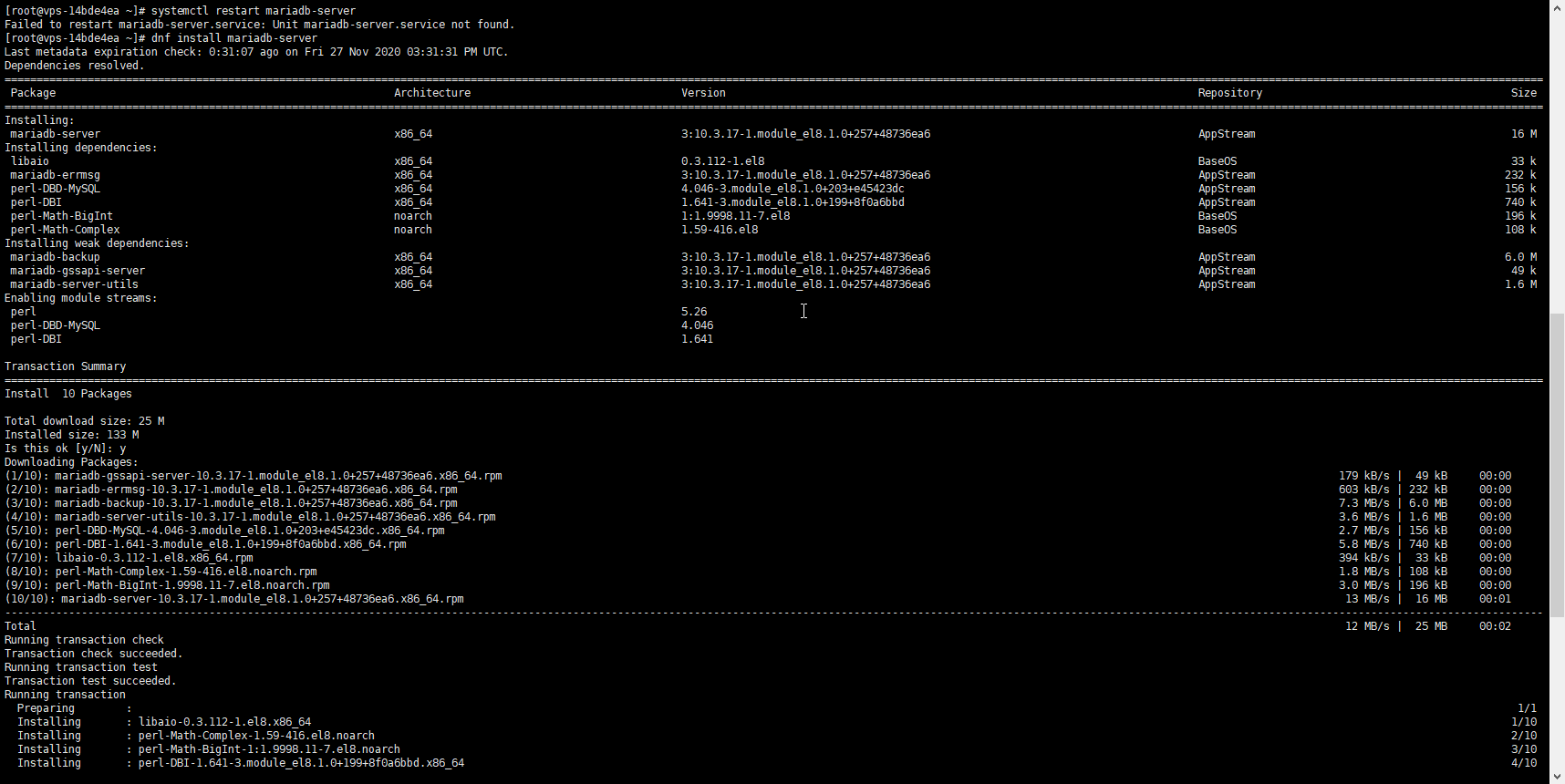
在 Centos 8 上,默认安装的 mariadb 服务器版本为:MariaDB Community Server 10.3 你只需要执行: dnf install mariadb-server 上面的命令进行安装就可以了。 运行结果 通过命令查看运行数据库的版本:systemctl status mariadb [root@vps-14bde4ea ~]# systemctl status mariadb ● mariadb.service - MariaDB 10.3 database server Loaded: loaded (/usr/lib/systemd/system/mariadb.service; enabled; vendor preset: disabled) Active: active (running) since Fri 2020-11-27 16:06:39 UTC; 9s ago Docs: man:mysqld(8) https://mariadb.com/kb/en/library/systemd/ Main PID: 16185 (mysqld) Status: "Taking your SQL requests now..." Tasks: 30 (limit: 11019) Memory: 85.2M CGroup: /system.slice/mariadb.service └─16185 /usr/libexec/mysqld --basedir=/usr Nov 27 16:06:39 vps-14bde4ea.vps.ovh.ca mysql-prepare-db-dir[16082]: See the MariaDB Knowledgebase at http://mariadb.com/kb or the Nov 27 16:06:39 vps-14bde4ea.vps.ovh.ca mysql-prepare-db-dir[16082]: MySQL manual for more instructions. Nov 27 16:06:39 vps-14bde4ea.vps.ovh.ca mysql-prepare-db-dir[16082]: Please report any problems at http://mariadb.org/jira Nov 27 16:06:39 vps-14bde4ea.vps.ovh.ca mysql-prepare-db-dir[16082]: The latest information about MariaDB is available at http://mariadb.org/. Nov 27 16:06:39 vps-14bde4ea.vps.ovh.ca mysql-prepare-db-dir[16082]: You can find additional information about the MySQL part at: Nov 27 16:06:39 vps-14bde4ea.vps.ovh.ca mysql-prepare-db-dir[16082]: http://dev.mysql.com Nov 27 16:06:39 vps-14bde4ea.vps.ovh.ca mysql-prepare-db-dir[16082]: Consider joining MariaDB's strong and vibrant community: Nov 27 16:06:39 vps-14bde4ea.vps.ovh.ca mysql-prepare-db-dir[16082]: https://mariadb.org/get-involved/ Nov 27 16:06:39 vps-14bde4ea.vps.ovh.ca mysqld[16185]: 2020-11-27 16:06:39 0 [Note] /usr/libexec/mysqld (mysqld 10.3.17-MariaDB) starting as process 16185 ... Nov 27 16:06:39 vps-14bde4ea.vps.ovh.ca systemd[1]: Started MariaDB 10.3 database server. [root@vps-14bde4ea ~]# 在上面的界面中,你可以看到运行服务器的版本。 通过这个命令,你可以看到当前的版本号。 https://www.ossez.com/t/centos-8-mariadb/738

完全不会丢失数据!所有你应用程序写入到磁盘的数据将会被完好的保存在容器中,直到你明确的删除容器。 在容器停止运行后,针对容器持久性的事件的文件系统还是在运行的。 https://www.ossez.com/t/topic/737
你可以在 Linux 和 Windows 的程序和执行 Docker 容器。 Docker 平台可以在原生的 Linux 上(x86-64, ARM 和更多其他的 CPU 架构)和 Windows(x86-64) 上运行。 Docker Inc. 构建产品,能够让你在 Linux, Windows 和 macOS 上构建和运行容器。 https://www.ossez.com/t/docker-linux-macos-windows/735
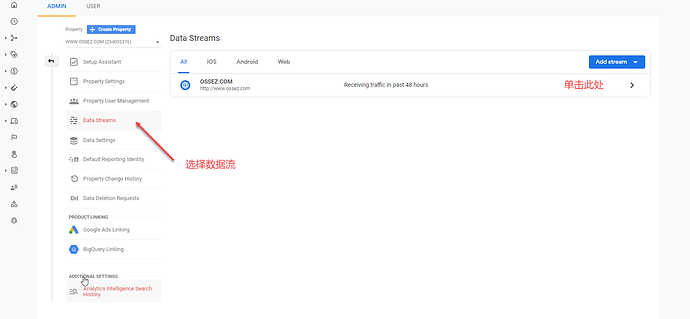
2020年10月14号,Google Analytics v4正式发布,由APP+Web改名而来的。 针对 Discourse 你可以非常容易的嵌入 GA4 的代码。 GA 4 是 Google Analytics v3 的升级版本,提供了更多的内容和亮点。 获得 GA 4 的 ID 在登录 Google Analytics 的控制台以后,选择数据流,然后在数据流下面有一个你命名网站的链接。 单击那个连接后面的箭头。 在弹出来的界面中,有一根 Measurement ID,这个 ID 是以字母 G 为开头的。 你需要拷贝这个内容。 添加到 Discourse 上 在 Discourse 上选择设置,然后搜索关键字 google 在结果上,有一根 GA Version 和 Tracking Code。 在 GA 的版本上,你需要选择 V4 的版本,否则将会显示的是 V3 的版本。 V3 的话,还是需要使用 UA 开头的代码,如果选择的是 V4 的话,你这里就复制上一步拷贝的 G 开头的代码就可以了。 校验安装 在完成设置后,登录 Google Analytics 的控制台,然后查看实时访问。 如果能看到有数据进入,就说明配置成功了。 https://www.ossez.com/t/discourse-google-analytics-ga4/734
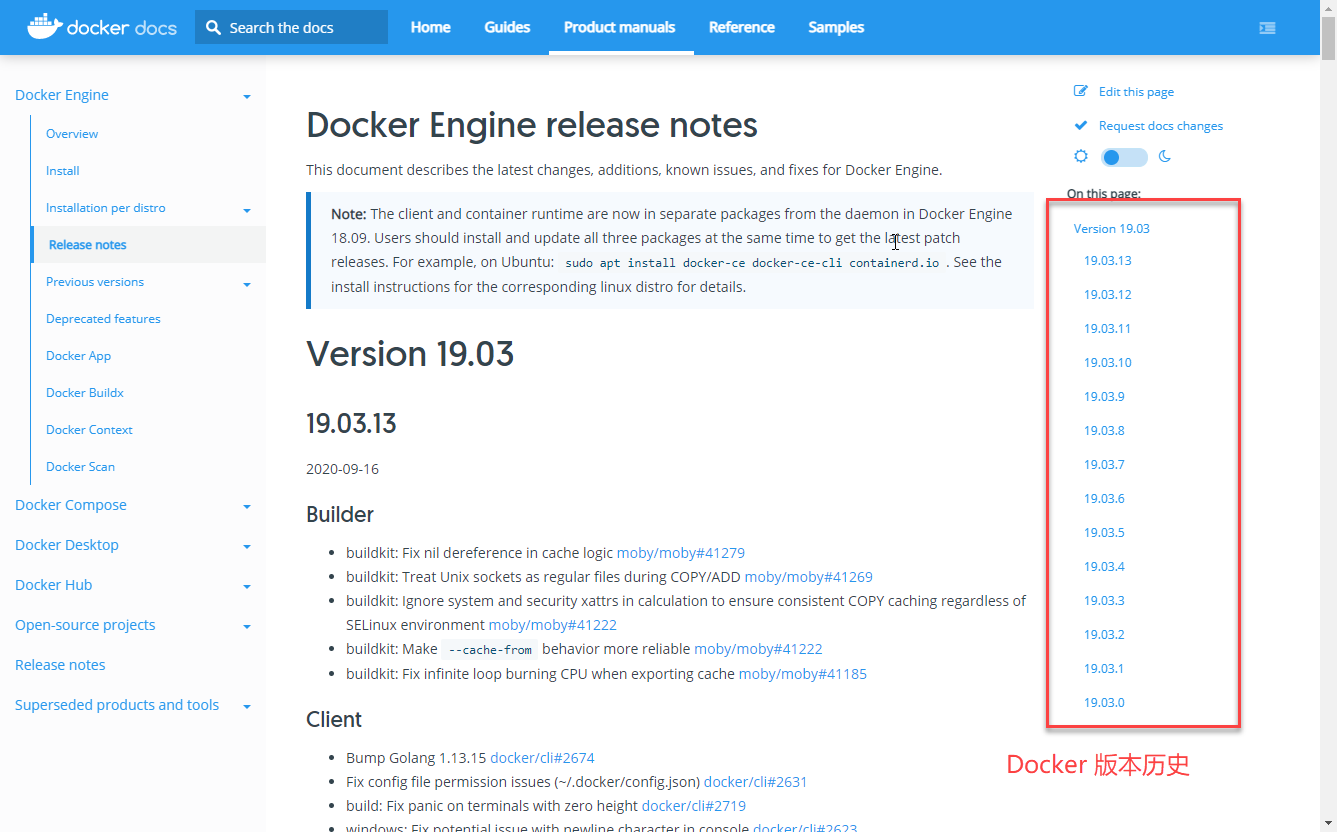
Docker 引擎具有下面 3 个更新渠道: stable, test 和 nightly: Stable 渠道提供给你最新可用的稳定版本。 Test 渠道提供了在发布之前的预览,被用于 general availability (GA) 之前的测试。 Nightly 渠道在针对下一个主要发行版本的每天晚间自动构建包。 稳定版 年-月(Year-month) 的分支将会发布到 master 分支中。这个分支将会使用下面的格式 <year>.<month> 来创建,例如 19.03。 年-月的命名由 GA 版本的最早确定的日历数据来进行确定。所有随后的特性补丁将会通过该版本号的序列来进行发布。例如,一旦 v19.03.0 版本发布后, 所有的后续发布的版本将会在基于 19.03 这个分支下来发布。 测试 在计划进行新的 year-month 的发布之前,一个分支将会从 master 分支进行创建,并被命名为 YY.mm。这个表明的是基于 Docker 里程碑的开放已经完成了。 一个预发布的测试版本的发布版本进行发布。发布的补丁和相关预发布的发布内容将会发布到发布的分支中。 晚间构建 晚间构建将会给个你一个基于下一个主要发布版本的最新构建,这个最新的构建有最新的特性和版本的修复。 0.0.0-YYYYmmddHHMMSS-abcdefabcdef 版本提交的 UTC 时间戳将会添加到发布版本的名称中,同时还会添加一个提交版本的哈希代码。如下:0.0.0-20180720214833-f61e0f7。 这个构建将会允许你使用最新的 master 分支来进行测试和构建。我们不能保证所有晚间构建能够正常的工作并且符合所有的安全性要求。 https://www.ossez.com/t/docker/731
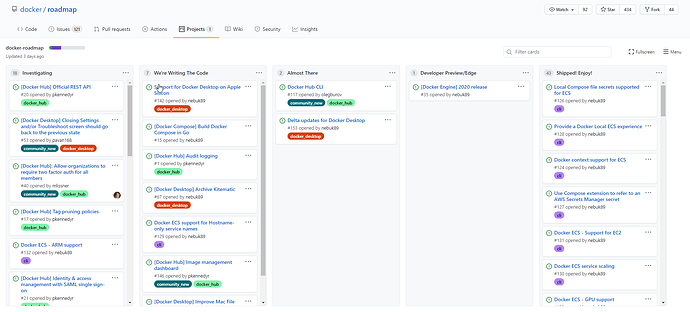
基于 年-月(Year-month) 格式的 Docker 引擎发布通常能够被支持一个月直到下一个月的 GA 版本发布。 这个意味着缺陷报告和可能的反向一致发布将会被评估知道达到发布版本的生命周期。 当基于 年-月(Year-month)发布格式的发布达到生命周期后,Git 仓库的分支有可能会被删除。 反向移植(backport) 反向移植是 Docker 公司针对 Docker 进行优先处理的问题。一个 Docker 公司的雇员或者代码仓库的维护人员将会进行评估和确定这些问题的修复能够被支持, 并确定你能够放到下一个 发布 的版本中。 如果你在提交代码的时候发现这个问题是一个比较重要的问题并且有可能面临反向移植(backport)问题。请确定在你提交的时候在提交内容高亮显示,你也可以在提交中明确说明。 升级路径 补丁的发布在升级的时候总是与基于 年-月(Year-month) 发布的版本是兼容的。 docker-roadmap-011920×869 125 KB 许可证 Copyright 2013-2020 Docker, inc, 文件的发布是基于 Apache 2.0 license 下进行发布。 Docker 是基于 Apache License, Version 2.0 许可证进行发布的。请查看 许可证 页面来获得更多的信息。 https://www.ossez.com/t/docker/732