因开发进程的需要,我需要修改一个工作空间的进程。 找了半天没有找到。 其实非常简单,选择你的工作空间后,单击名字就可以了。 上面有个小窍门的地方就是你需要把鼠标移动到工作空间的名字上面。 https://www.ossez.com/t/postman/13827
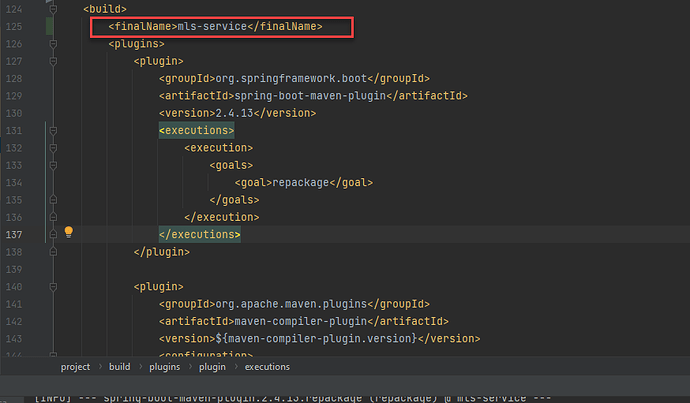
Spring Boot 打包的时候如果不进行配置的话将会在生成的包中添加版本名字。 如果你不希望在生成的包中添加版本名字的话,你需要在 maven 的 pom.xml build 部分添加: <finalName>mls-service</finalName> 这样打包成的 jar 包将会被命名为: mls-service.jar 如上图的配置。 https://www.ossez.com/t/maven-spring-boot-jar/13826
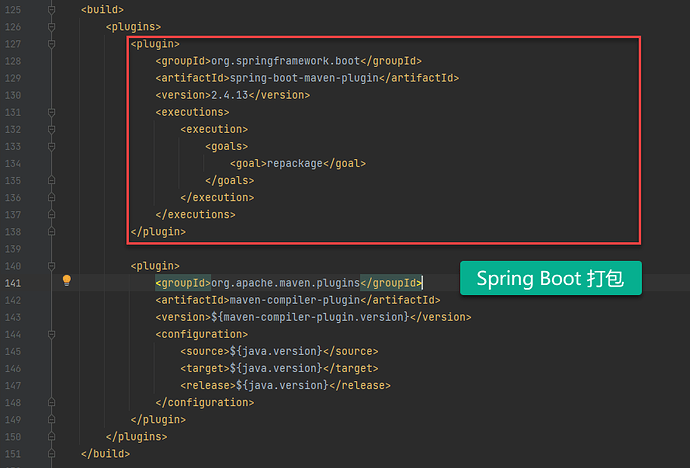
如果你使用的是 Maven 开发 Spring Boot 项目的话,在你打包可执行文件的时候,你首先需要导入 spring-boot-maven-plugin 插件。 请查看下面的代码: <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> <version>2.4.13</version> <executions> <execution> <goals> <goal>repackage</goal> </goals> </execution> </executions> </plugin> </plugins> </build> 上面的代码在 Package 的时候将会把你的 Spring 项目打包成一个可以执行的 jar。 如上图显示的内容,然后再执行下面的命令来进行打包: mvn package 打包成功后就能在 target 目录中看到上面的 2 个文件了。 上面就是使用 maven 打包后的命令生成的可执行文件,你可以直接使用 java -jar 来执行。 https://www.ossez.com/t/maven-spring-boot/13825
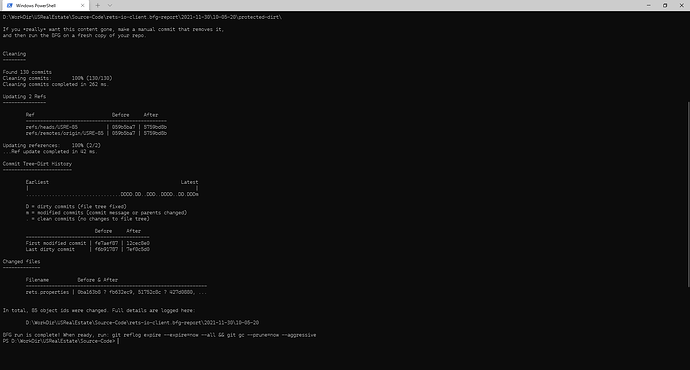
有时候我们会在属性文件中添加数据库的连接参数等。 但是在提交的时候不小心将这些敏感连接参数和密码也提交到服务器上了。 虽然很多公司都有防火墙只能内部访问,但是还是非常不安全的。 这时候你需要一个 BFG Repo-Cleaner 这个工具了。 这个工具主要用于清理仓库中的敏感文本包括提交历史记录中的,同时也一并将历史记录清理。 下载 下载地址为:BFG Repo-Cleaner by rtyley ,你会下载一个 jar 的包。 假设我们需要清理仓库名称为:rets-io-client,你首先需要将这个仓库克隆到本地。 然后把下载的包放在和这个仓库同级的目录中。 假设我们的仓库地址为:D:\WorkDir\USRealEstate\Source-Code\rets-io-client 那么你可以将这个包放在:D:\WorkDir\USRealEstate\Source-Code 目录下面。 同时在 D:\WorkDir\USRealEstate\Source-Code 目录下面创建一个 passwords.txt 文件 运行命令 在控制台中运行下面的命令: java -jar bfg-1.14.0.jar --replace-text passwords.txt rets-io-client 将你需要替换的字符串放到 passwords.txt 文件中。 例如我们需要替换的密码为 jfnsV4yHsDYaX4x9 那么你需要将这个字符串添加到 passwords.txt 后再执行上面的命令。 运行后的结果如上图的内容。 如果你有多个字符串需要替换的话,可以重复上面的操作。 在完成上面的所有替换后,进入仓库分别执行下面的 2 条 git 命令。 git reflog expire --expire=now --all 和 git gc --prune=now --aggressive 如果一切都没有问题的话,再运行 git push 将修改推送到远程仓库中。 此时再查看你的提交记录,所有敏感字符串应该都被替换掉了。 在提交历史中的字符串也会被替换成不可见的字符了。 https://www.ossez.com/t/git/13822

面试的时间是在 2021 年的 11 月初开始的。 从投递简历开始到拒绝一共经历了 4 轮,在第 4 轮代码的过程中被拒绝。 拒绝的理由是,提交的代码没有完成题目指定的目的,目前他们找到比我更牛逼的人了。 对这个理由,我只能是呵呵一笑,在本文的最后我会把题目和我的代码作为附件发出来,供有精力跑跑的同学去看看吧。 大家看看到底是不是这个原因?还是只能说这个团队是奇葩,其实我们也不能上升公司层面,可能就是这个团队是奇葩罢了。 相关背景 公司方向是做金融和资产管理的。 虽然公司是做金融和资产管理,但是并不是所有 IT 都和这个有关系的,应该是公司内部希望做一个处理项目等。 HR 是白人,相对来说还是比较好沟通,具体面试的人是印度人,谈不上难沟通,其实还是比较好说话的,整个面试的 1 个小时还是非常顺利。 在面试完成后的第二天,发了一个代码题目过来,希望我完成。 这个题目说是有 3 个小时去完成,其实是一个设计题目,并不需要在线代码,也没有完全的时间限制,具体自己掌握。 在提交代码后的 3 天,他们给出了上面的结论。 第一轮 —— 公司介绍和技术 第一轮是电话沟通,在投了简历后的不久,HR 有人联系我说约个时间来电话详细聊一下。 聊天的内容还是非常多的,主要有你曾经做过的想,Java 有关 OOP 的内容,多线程,关键字,设计模式等等。 多线程是如何进行控制和调试的,关键字有哪些,你是如何进行编码的。 个人感觉这部分的内容还是非常多的,你需要对 Java 的多线程和线程安全有些了解才能答得上来。 第二轮 —— 技术面试 这个部分是 Zoom 的在线视频面试。 这部分面试的人是一位印度女性,她的语言没有什么印度口音,发音还算是非常清晰。 在这部分中主要讨论了我曾经做的一些项目,和在这些项目中有些什么样的问题。 同时在这部分对 Java 数组的遍历有过一些讨论,这里主要还是讨论了线程安全的问题,比如说遍历上面会不会有线程安全的考虑等等。 整个过程还是非常轻松的,问题不大。 第三轮 —— 代码 出问题的地方在这轮。 其实这个也没有什么好说的下面就是他们代码要求的问题: 为了不找麻烦,我将内容截图了。 下面就是中文的土话解释了: 实现一个租车系统,使用的是 OOP。 这个系统允许完成对车的预订:给定的参数是车的类型,预订时间和天数。 车的类型有 3 种类型,同时使用 Unit 测试 今天再次阅读这个题目后,我的测试应该是完成了车的预订,因为题目没有说要对还车进行考虑和逻辑设计,所以我只做到了返回确认码。 我认为这个题目的主要目的是考察 OOP 的问题,而不是完成整改逻辑流程,因为题目来看并没有要求完成还车等逻辑流程。 代码请参考附件。 Demo-Cars-Rental-main.zip (41.6 KB) 本来这个代码是放在 GitHub 上的,为了不找麻烦,我就作为附件上传了。 运行结果为: 上面显示了完成预订后的确认码。 总结 针对上面的回复我的想法还是呵呵的。 这显然有点奇葩的回复,你出的这个题目的目的是什么呢?不就是要考察对 OOP 的使用和对象设计处理能力吗? 如果面试只是纠结这个逻辑是不是完成了,而毫不关心对面向对象的使用,框架的使用,设计能力,编译能力的考察的话,我只能说是有点奇葩了。 同学们,你们怎么看? 欢迎在下面留言,讨论。 https://www.ossez.com/t/topic/13820
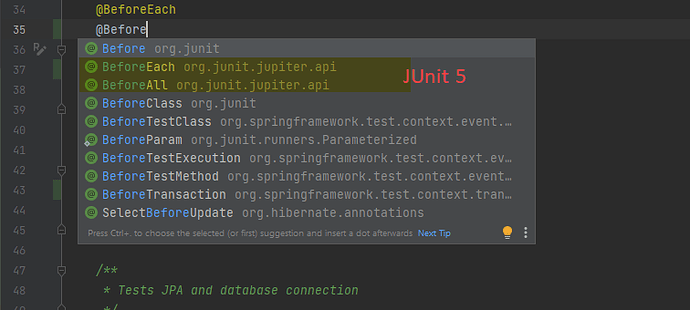
概述 在本简短教程中,我们分别对 @Before、@BeforeClass、 @BeforeEach 和 @BeforeAll 注解来进行一些简短的说明和实践。 需要注意的是,针对 Junit 版本的不: JUnit 4 对应使用的是: @Before 和 @BeforeClass JUnit 5 对应使用的是: @BeforeEach 和 *@BeforeAll 虽然名字有所改变,但是目的是相同的,并且功能都是向对应的。 另外,与其完全相对的还有一个就是 @After 的注解。 让我们从 JUnit 4 开始 @Before 这个注解是在 JUnit 4 中使用的。 使用这个注解的意思就是在测试类中,每一个测试开始执行之前都需要执行这个注解标记的方法。 通常用在我们希望对所有测试在执行之前都需要执行的方法。 让我们先对一些值进行初始化: @RunWith(JUnit4.class) public class BeforeAndAfterAnnotationsUnitTest { // ... private List<String> list; @Before public void init() { LOG.info("startup"); list = new ArrayList<>(Arrays.asList("test1", "test2")); } @After public void teardown() { LOG.info("teardown"); list.clear(); } } 请注意,在这里我们还在后面添加了一个 @After 注解,这个注解的意思是在每一个测试执行后都会对列表进行清理。 现在,我们添加一些测试来检查我们 List 了列表的大小: @Test public void whenCheckingListSize_thenSizeEqualsToInit() { LOG.info("executing test"); assertEquals(2, list.size()); list.add("another test"); } @Test public void whenCheckingListSizeAgain_thenSizeEqualsToInit() { LOG.info("executing another test"); assertEquals(2, list.size()); list.add("yet another test"); } 在本测试用例中:**针对每一个测试方法,确保所有的测试环境是相同的对每一个测试都非常重要。**在本用例中,我们主要需要确保变量的初始化是完全相同的,这是因为每一个测试方法在执行的时候都会对初始化后的变量进行修改。 随后,我们对输出的数据进行查看的时候,我们会发现针对每一个测试方法在执行的时候 init 和 teardown 方法都会在测试执行之前执行一次。 ... startup ... executing another test ... teardown ... startup ... executing test ... teardown @BeforeClass 针对每次测试执行的之前都要执行的方法相比,我们希望使用 @BeforeClass 这个注解。 这个注解的意思是针对测试类中的所有测试方法,只执行一次。 针对一些开销比较大的方法,你可能希望在所有方法执行之前只执行一次,比如说数据库连接和启动某个系统,这个时候你就可以使用 @BeforeClass 这个注解来执行标记的方法了。 让我们来创建一个与上面相同的测试类,不同的是我们使用了不同的注解。 @RunWith(JUnit4.class) public class BeforeClassAndAfterClassAnnotationsUnitTest { // ... @BeforeClass public static void setup() { LOG.info("startup - creating DB connection"); } @AfterClass public static void tearDown() { LOG.info("closing DB connection"); } } 需要注意的是,**上面的这些方法必须是静态方法(static)**因为这些方法将会在 test 测试之前先行执行。 随后,让我们添加一些简单的测试: @Test public void simpleTest() { LOG.info("simple test"); } @Test public void anotherSimpleTest() { LOG.info("another simple test"); } 这次,如果你查看测试方法的输出后,你会看到我们标记的方法只在所有测试开始执行之前执行了一次。 控制台的输出如下: ... startup - creating DB connection ... simple test ... another simple test ... closing DB connection @BeforeEach 和 @BeforeAll @BeforeEac 和 @BeforeAll 是 JUnit 5 中的注解,这个注解与 JUnit 4 中的 @Before 和 @BeforeClass 是完全对应的。 这 2 个注解在 JUnit 5 中被重命名的原因主要是为了避免冲突。 你可以拷贝上面的方法,然后使用 JUnit 5 的注解来重新注解: @BeforeEach 和 @AfterEach @RunWith(JUnitPlatform.class) class BeforeEachAndAfterEachAnnotationsUnitTest { // ... private List<String> list; @BeforeEach void init() { LOG.info("startup"); list = new ArrayList<>(Arrays.asList("test1", "test2")); } @AfterEach void teardown() { LOG.info("teardown"); list.clear(); } // ... } 然后你可以对程序的输出日志进行查看,你会看到与 @Before 和 @After 注解是完全对应的: ... startup ... executing another test ... teardown ... startup ... executing test ... teardown 最后,你可以重新注解下 @BeforeAll 和 @AfterAll 再进行测试: @RunWith(JUnitPlatform.class) public class BeforeAllAndAfterAllAnnotationsUnitTest { // ... @BeforeAll public static void setup() { LOG.info("startup - creating…
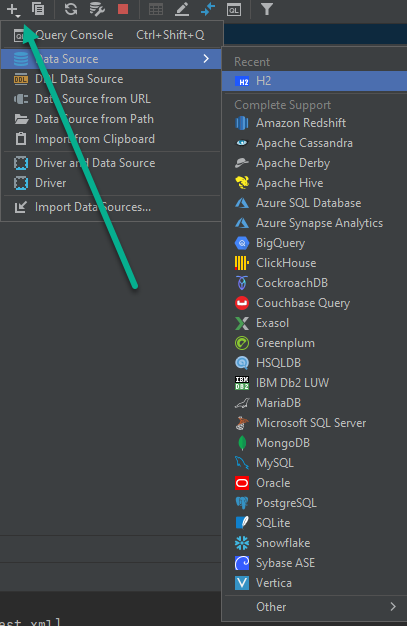
有时候我们希望使用 IntelliJ IDEA 来查看下数据库中的数据情况,尤其是针对 H2 使用的数据库。 创建连接 首先单击数据库连接上面的 + 号。 然后选择 H2 数据库。 配置数据库参数 随后需要对数据库的连接参数进行配置。 如果你当前的数据库使用的是文件系统的数据库的话,那么你需要选择嵌入方式。 如果数据库的配置使用的是内存数据库的话,你可以针对的选择使用内存数据库。 然后在 URL 部分输入你的数据库配置参数。 随后单击 测试连接 来对连接进行测试。 如果没有问题的话,将会返回测试成功的结果。 查询数据 在完成上面的配置后,你可以重新打开数据库连接的窗口。 然后通过单击表格对数据进行查询。 对表格的查询结果将会显示在界面的左侧表格中。 https://www.ossez.com/t/intellij-idea-java-h2/13817

H2 是我们常使用的一个内存数据库,通常这个数据库能够帮助我们在测试的时候进行逻辑测试。 如果你使用了 Hibernate 的话,首先需要设置数据库的连接,因为 H2 可以支持内存模式,也可以支持文件模式,我们下面分别对这 2 种模式的配置参数进行一些解读。 内存模式 我们可以使用下面的配置的字符串来进行内存模式的配置: hibernate.connection.url=jdbc:h2:mem:test;MODE=MySQL;DB_CLOSE_DELAY=-1;DB_CLOSE_ON_EXIT=FALSE;INIT=RUNSCRIPT FROM 'classpath:schema/h2.sql' 针对内存模式,需要了解下面的重点,在 JVM 进程启动后,将会在内存中创建一个数据库,当 JVM 内存释放后,你的程序将会关闭最后的连接,当 H2 直到最后的连接被关闭后,H2 数据库将会自动从内存中删除。 jdbc:h2:mem:test 上面的命令将会在内存中创建一个 test 的数据库,这个参数中的 mem 表示的是内存中创建。 MODE=MySQL 创建的数据库使用 MySQL 兼容模式,这样如果你需要对数据库迁移到基于服务器的 MySQL 数据库上的话,你不需要对你的逻辑代码和实体进行修改。 DB_CLOSE_DELAY=-1 在默认情况下,H2 将会在最后的连接退出的时候关闭数据库。针对基于内存的数据库配置的情况下,如果在这个情况下还进行数据库连接的话,很有可能程序将会得到连接丢失的错误,如果你使用了连接池的话,通常在 JVM 退出之前,连接池都会保持有数据库连接,因此这个问题针对使用连接池的情况可能不存在。 如果你没有使用连接池的话,建议将这个参数设置为: ;DB_CLOSE_DELAY=-1 这样能够保证在虚拟机退出之前 H2 数据库不关闭连接。 DB_CLOSE_ON_EXIT=FALSE 这个参数的默认配置为 TRUE。 在默认情况下,H2 将会在最后的连接退出的时候关闭数据库,如果在这个情况下数据库没有被关闭的话,H2 将会在虚拟机退出的时候关闭数据库。 但是在一些特殊的情况下,我们并不希望虚拟机在退出的时候关闭数据库,比如说你还需要使用数据库写入一些虚拟机的情况,或者写入虚拟机的关闭过程等。 因此,在这个情况下,你需要讲这个参数配置为 TRUE。 INIT=RUNSCRIPT FROM ‘classpath:schema/h2.sql’ 初始化 SQL 脚本。 通常我们会在这里配置一个初始化的脚本,因为内存数据库在初始化成功后是不会创建数据表和初始化数据的,因此我们需要让第一个链接在链接数据库后直接运行一个脚本来创建数据库,表,同时插入一些数据。 这个配置是在这里设置,classpath: 就是你当前项目的 resources 目录中。 如果下图所示的目录结构。 文件模式 文件模式的情况能够让你的测试数据在文件系统中持久化。 这种模式通常能够让有机会在程序退出的时候检查数据处理是否准确,存储和更新是否有问题。 hibernate.connection.url=jdbc:h2:file:~/h2/test;MODE=MySQL;AUTO_SERVER=TRUE 请参考上面的配置参数,和下面的一些解读。 jdbc:h2:file:~/h2/test 这个配置参数会告诉 H2 在文件系统中创建一个数据库,创建的路径为 ~/h2/test 具体来说,如果你使用的是 Windows 系统,并且当前登录的用户名为 huyuc,那么创建的数据库文件的路径为:C:\Users\huyuc\h2 AUTO_SERVER=TRUE 这个配置模式为 Automatic Mixed Mode。 用土话说就是允许多个进程同时访问数据库。 举例来说,如你运行一个测试环境,但是又想用一个 UI 工具来查看数据库中的数据情况,这个时候你需要讲这个配置参数设置为 TRUE。 因为这里是 2 个进程同时访问数据库,否则你将会得到数据库文件被占用的错误。 https://www.ossez.com/t/hibernate-h2-url/13816
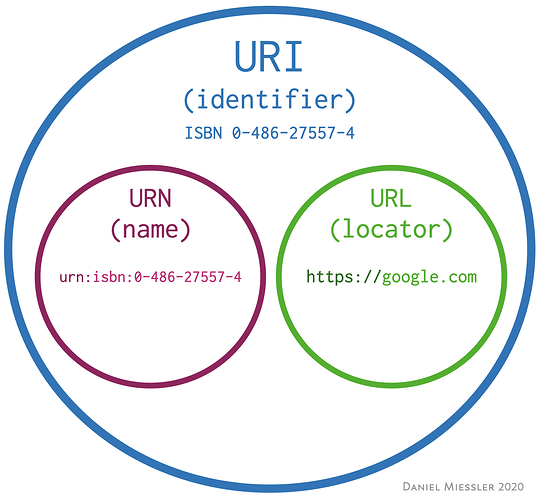
面试的时间是在 2021年的 11 月。 在第一轮面试进行一些沟通情况的后就没有下文了。 相关背景 本次面试的原因是有招聘的 HR 在 Linkedin 上找到我,发了一个希望了解下的消息,然后先消息了解了下。 这个公司本身应该是做的 IoT 相关的服务的,这个公司在 2019 年我没事投简历后发过一次 OA 给我,费了不少时间做完成 OA 后基本上就没有下文了。 个人觉得上次的 OA 没有什么问题,结论都是正确的。所以这次他们找我希望再次沟通下,我也真没有太当会事情,因为我知道这家公司基本上是属于面试面着玩的那种,公司在招聘层面的逻辑和流程本身也不是非常正规。 第一轮面试相关 第一轮面试是完全的电话沟通,没有任何深入的了解,主要是面试的人不知道从哪里搬来了一些概念来问你了解不了解。 问得最多的是技术栈上面的问题,主要是设计上面的。 同时还问了一个 Restful API 是什么东西,会有些什么。如果你做过相关 API 的话,通常这个不会非常难,一般都是 POST Payload,同时在 Header 里面会设置一些参数等等。 因为我是使用 Java 技术栈的,因此多用 Spring MVC 来构建一个 API 就可以了。 另外一个问题就是什么是 URL 和 URI,这个问题就有点意思了,通常 URL 都是统一资源定位符的简称,在网页上输入的都是 URL。 URI = Uniform Resource Identifier 统一资源标志符 URL = Uniform Resource Locator 统一资源定位符 通常知道 URL 为 URI 的子集就好了。 这 2 个都有点概念性的意思了,其实很多时候我们都不会过于深究到底是 URI 还是 URL,所以说都不明白这个问题是从哪里抄过来的。 总结 感觉主要还是技术栈不是非常符合的意思,这个公司原来使用的是 Java 技术栈,随着时间变化,感觉他们要将技术栈迁移到 NodeJS 上了。 因此他们可能要求更多的 NodeJS 后端编程开发的,但是 NodeJS 本身可能不适合非常大逻辑的计算等,并且 NodeJS 的包的质量普遍没有 Java 高。 当然技术是为业务服务的,公司的选择无可厚非。 另,因为没有听清他们要求解释 URL 还是 URI,所以这个有关 URL 和 URI 的问题压根就没有回答明白,上面的内容都是后面自己脑补的。 https://www.ossez.com/t/iot/13815
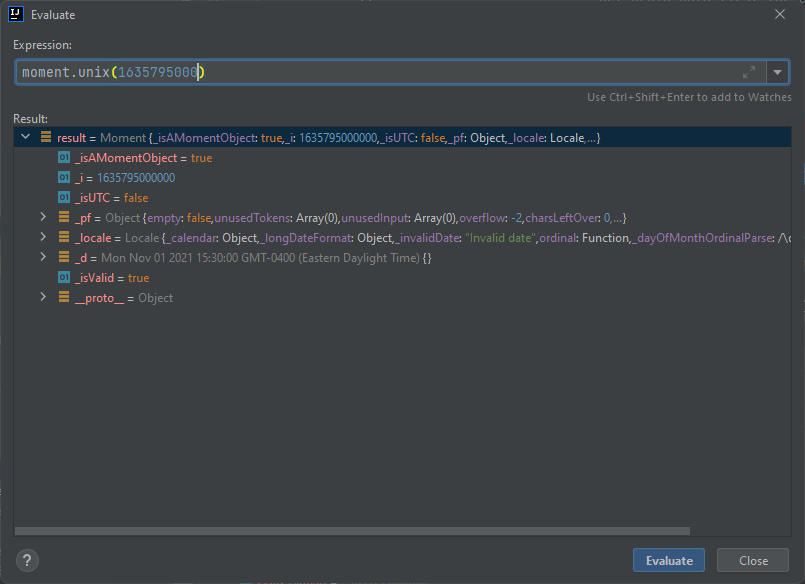
如果你对 Epoch 不是非常了解的话,请参考下下面的帖子: UNIX时间:新纪元时间(Epoch Time) Moment.js 是可以直接使用数字来构造 Moment 对象的。 需要注意的是 Epoch 时间可能有 2 个数字。 对比下面 2 个数字: 1635795000000 1635795000 其实都表示的是一个时间,不同的是第一个数字带上了毫秒,第二个数字没有。 那么在构造 Moment 对象的时候使用的方法是不同的。 对一个数字,我们应该使用: moment(1635795000000) 直接构造就可以了。 对第二个数字,应该使用的方法是,moment.unix(1635795000) 从输出中,我们可以看出来,如果使用了 .unix 的方法的话,会自动在你的输入数据之后添加 3 个 0。 总结 Moment 对象内部使用的是毫秒级别的保存,因此在构造的时候如果使用的是数字来构造对象。 你需要考虑使用的方法,否则可能会出现不正确的情况。 https://www.ossez.com/t/moment-js-epoch-time/13812