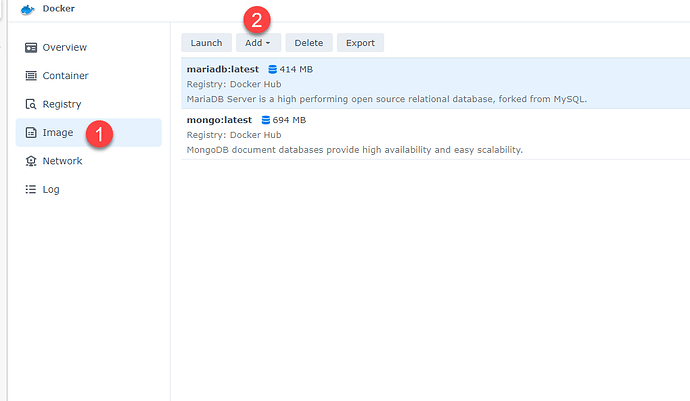
首先需要在群晖的 Docker 中选择 Image,然后选择添加。 输入 Docker HUB 的地址 在弹出的对话框中输入 Docker Hub 的地址。 MongoDB 的地址为: Docker Hub 然后选择添加。 选择版本和运行 在后续的界面中,要求选择版本,我们选择最新的版本即可。 随后,我们需要稍等下把 Image 下载到整列中。 然后选择 Mongo 的版本运行即可,网络按照默认的选择。 下一步继续。 在下一个界面中需要对本地网络进行映射。 对卷进行配置,在默认情况下,可以跳过这一步。 对配置进行校验。 如果没有问题的话,直接下一步进行安装。 启动服务 在安装好的服务中,单击启动 Mongo 服务就可以了。 通过日志来查看启用的状态。 根据你 NAS 的情况不同,你可能没有办法安装到 MongoDB 的最高版本。 这个时候可能你只能用到 4.x 的版本。 如果能够在控制台上看到下面的内容,则说明已经安装成功了。 https://www.ossez.com/t/synology-nas-mongodb/14152
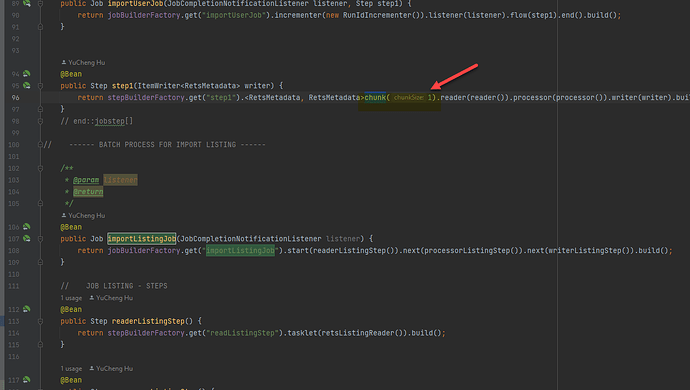
我们都知道 Spring Batch 有 2 种任务方式。 主要是在 Step 阶段,在 Step 阶段,我们可以执行一个 Tasklet,我们也可以按照 Chunk 来执行。 主要区别 如果使用 Tasklet 的话,我们可以一个 Step 对应一个 Tasklet,Spring Batch 不允许一个 Step 对应多个 Tasklet。 考虑有一个场景,我们需要使用 Spring Batch 对数据库中的表进行更新,这个表可能每次 Batch 要更新 几千条数据,需要满足每 5 分钟更新一次。 如果我们采取 Tasklet 的方式的话,正常的思维都是读取需要更新的数据,然后逐条进行更新。 这个没有问题吧,但是恰恰问题就在这里。 问题就是在 Spring Batch 使用的事务,Tasklet 在启动的时候会创建一个事务,那么读取 1000 条数据,处理 1000 条数据,写入 1000 条数据都在一个事务里面。 假设这个处理时间超过 5 分钟,下一次的任务又开始启动了,这个时候 Spring Batch 还会启动一个事务。 假设 10 分钟了,我们还是没有完成,Spring Batch 会继续启动任务和创建事务。 结果是什么,这个显而易见了,就是出现事务堆积,导致锁表,然后所有的任务都失败,无法完成。 针对这种场景,我们就需要 chunk 了。 chunk Chunk 的主要目的就是为了告诉 Spring 一次执行几条记录。 我们如果设置 Chunk 为 1 的话,那么 Spring Batch 每次读取一条记录,处理一条记录,写入一条记录,然后将这个事务进行提交。 这样的话,可以有效的避免事务堆积导致的锁表。 Chunk 的大小,通常比较小,如果一次性设太大了,也会锁表。 https://www.ossez.com/t/spring-batch-chunk/14151
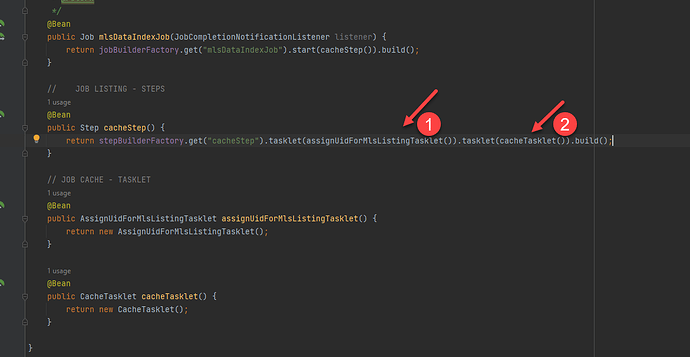
根据 Spring Batch 的设计,在一个 Step 中只能执行一个 Tasklet。 如果想按照顺序执行多个 Tasklet 的话,我们需要设置不同的 Step。 正如上面定义的 Step,虽然我们在这个 Step 中定义了 2 个 Tasklet。 上面代码最后的执行顺序还是只执行最后一个 Tasklet,第一个定义的被忽略掉了。 https://www.ossez.com/t/spring-batch-step-tasklet/14150
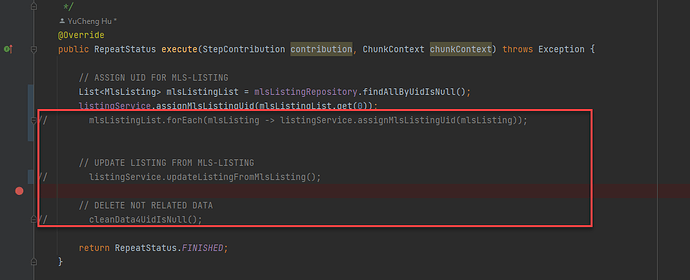
对 Spring Batch 有所了解的同学都知道 Batch 是用来进行批量数据处理的。 但是我们在同时使用 Spring JPA 的时候,尤其是循环数据处理的时候,我们希望能够尽快提交事务。 但是,Spring Batch 中,如果使用了 Tasklet 的话,那么Spring 会在 Tasklet 级别创建一个事务。 在 Tasklet 不完成的情况下,事务是不会提交的。 这就需要对我们代码进行进行处理的时候,需要对数据量有多大有比较清楚的了解。 否则,非常容易遇到事务堆叠导致锁表的情况。 解决办法 针对一个 Tasklet 只完成一个特定的工作,如果 Job 的处理数据比较多的话,需要分开不同的 Tasklet 来做。 如上图,哪怕我们在这里调用了不同的服务,调用了不同的数据层。 事务都是没有办法提交的。 简单的办法就是针对上面的操作使用不同的 Tasklet 来做。 有人问过,能不能在循环中一次一次的进行提交。 Spring Batch 这样设计的目的就是为了保持数据的完整性,因此需要对 Batch 的逻辑进行考虑,而不建议考虑怎么省事怎么来。 https://www.ossez.com/t/spring-batch/14148
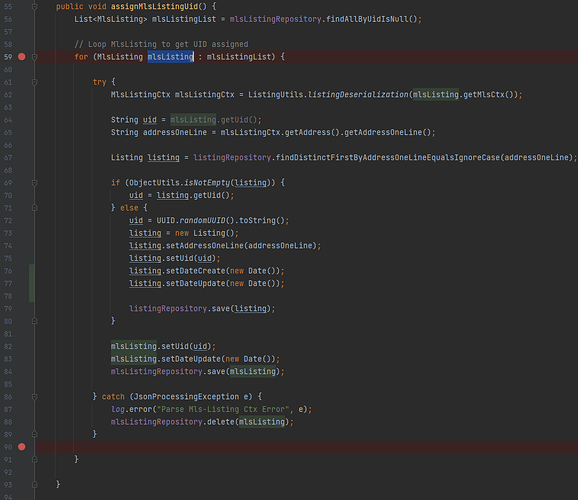
在 Spring 项目中,如果使用了 Spring 的事务管理的话。 默认的事务级别都在类,这个级别的,这就导致了,如果在循环中对数据进行处理的话,如果循环不结束,事务是不会提交的。 如果出现了事务堆积的情况,大概率就会锁表,然后整个服务抛出异常。 如下面的代码: public void assignMlsListingUid() { List<MlsListing> mlsListingList = mlsListingRepository.findAllByUidIsNull(); // Loop MlsListing to get UID assigned for (MlsListing mlsListing : mlsListingList) { try { MlsListingCtx mlsListingCtx = ListingUtils.listingDeserialization(mlsListing.getMlsCtx()); String uid = mlsListing.getUid(); String addressOneLine = mlsListingCtx.getAddress().getAddressOneLine(); Listing listing = listingRepository.findDistinctFirstByAddressOneLineEqualsIgnoreCase(addressOneLine); if (ObjectUtils.isNotEmpty(listing)) { uid = listing.getUid(); } else { uid = UUID.randomUUID().toString(); listing = new Listing(); listing.setAddressOneLine(addressOneLine); listing.setUid(uid); listing.setDateCreate(new Date()); listing.setDateUpdate(new Date()); listingRepository.save(listing); } mlsListing.setUid(uid); mlsListing.setDateUpdate(new Date()); mlsListingRepository.save(mlsListing); } catch (JsonProcessingException e) { log.error("Parse Mls-Listing Ctx Error", e); mlsListingRepository.delete(mlsListing); } } } 这个方法,在循环执行完成之前是不会提交事务的。 上面的代码只要部署到服务器上,一旦需要处理的量稍微大一点点,肯定锁表。 解决办法 解决办法就是把循环从 Services 层中拿出来。 放到另外一层,这样的话就能够在循环中进行提交。 https://www.ossez.com/t/spring/14147
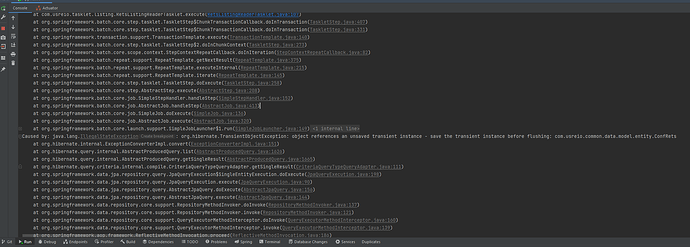
错误的信息为: Caused by: java.lang.IllegalStateException: org.hibernate.TransientObjectException: object references an unsaved transient instance - save the transient instance before flushing 问题和解决 出现这个问题的情况有很多。 比如说在对多的关系中,没有进行映射,或者 Lazy Load 的问题的。 在这个地方的问题,我们的情况是调用 Repository 发送了一个空对象。 MlsOffice mlsOffice = mlsOfficeRepository.findDistinctFirstByMlsOfficeIdEqualsAndConfRetsEquals(officeId, new ConfRets()); 我们可以通过后面 new 一个对象,然后再进行查询。 这个查询将会重现上面的错误。 因此,我们需要确定在查询的时候发送到后端的对象不应该为 null。 在代码中进行空对象检查是有必要的。 https://www.ossez.com/t/spring-jpa-org-hibernate-transientobjectexception/14145
有时候我们需要将给定的 List 转换为 Map。 如果你使用的是 Java 8 以后版本的话,Stream 是你的好朋友。 Java 8 public Map<Integer, Animal> convertListAfterJava8(List<Animal> list) { Map<Integer, Animal> map = list.stream() .collect(Collectors.toMap(Animal::getId, Function.identity())); return map; } 上面的代码可以非常容易的完成转换,我们有一个 Animal 对象的 List。 上面的代码将会把 Id 作为 Key,然后生成的 Map 是以 id 为 Key,Animal 为Value 的 Map。 Guava 如果使用 Guava 就更加简单了。 public Map<Integer, Animal> convertListWithGuava(List<Animal> list) { Map<Integer, Animal> map = Maps .uniqueIndex(list, Animal::getId); return map; } 使用 Maps 的工具类就可以了,这个工具类可以直接用。 更进一步 如果对需要生成的 Map 进行处理。 Key 是对象中的一个值,Value 是 List 对象中的另外一个值。 例如可以使用下面的代码: listingStatusList.stream().collect(Collectors.toMap(CListingStatus::getListingStatusKey, CListingStatus::getListingStatus)); 其中 CListingStatus 对象是这样定义的。 @Entity @Getter @Setter public class CListingStatus extends AbstractPersistable<Long> { @ManyToOne @JoinColumn(name = "rets_id", nullable = false) private ConfRets confRets; private String listingStatusKey; private ListingStatus listingStatus ; } 对 Map 中的对象设值 针对 Stream 中的对象,我们可能还需要重新设置为其他的对象。 这个时候我们就可以使用 lambda 函数了。 同样的代码: HashMap<String, Agent> agentHashMap = (HashMap) mlsAgentList.stream().collect(Collectors.toMap(MlsAgent::getMlsAgentId, mlsAgent -> { Agent agent = new Agent(); agent.setAgentId(mlsAgent.getMlsAgentId()); agent.setAgentNameFirst(mlsAgent.getNameFirst()); agent.setAgentNameLast(mlsAgent.getNameLast()); agent.setAgentEmail(mlsAgent.getEmail()); return agent; })); 我们返回的 Map 使用了一个新的对象为 Value。 上面针对 Stream 转换为 Map 的方法进行了一些小总结,这些方法可能实际编程的时候使用的频率比较高。 同时能够避免大量使用 For 循环的情况。 Stream 还是需要好好了解下的。 https://www.ossez.com/t/java-list-map/14144
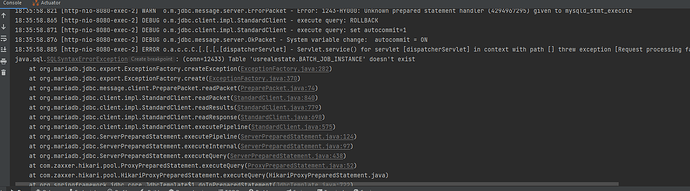
在运行 Spring Batch 项目的时候,提示上面的错误信息: java.sql.SQLSyntaxErrorException: (conn=12433) Table 'usrealestate.BATCH_JOB_INSTANCE' doesn't exist 问题和解决 这个问题如果是使用 Hibernate 的会话,没有使用 Spring JPA 的话,通常是不会提示的。 如果你在 application.properties 文件中配置了数据库连接的话,通常会提示上面的错误。 这是因为,如果你没有使用 Spring JPA 的话,Spring Batch 会启用一个 H2 数据库,在这个数据库中,Sping 会对 Batch 需要的配置进行配置。 如果你使用 Spring JPA 的话,你需要 Spring Batch 帮你初始化表。 解决办法就是在项目配置文件中,设置: spring.batch.initialize-schema=ALWAYS 但是上面的内容会显示为被丢弃了。 在 2.7 的 Spring Boot 版本中,应该使用的配置为: spring.batch.jdbc.initialize-schema=ALWAYS 如果使用的是 IDEA 的话,上面的内容会自动提示。 当你第一运行你的项目的时候,数据库会创建下面一堆表。 18:46:43.516 [main] DEBUG o.m.jdbc.client.impl.StandardClient - execute query: CREATE TABLE BATCH_JOB_EXECUTION ( JOB_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY , VERSION BIGINT , JOB_INSTANCE_ID BIGINT NOT NULL, CREATE_TIME DATETIME(6) NOT NULL, START_TIME DATETIME(6) DEFAULT NULL , END_TIME DATETIME(6) DEFAULT NULL , STATUS VARCHAR(10) , EXIT_CODE VARCHAR(2500) , EXIT_MESSAGE VARCHAR(2500) , LAST_UPDATED DATETIME(6), JOB_CONFIGURATION_LOCATION VARCHAR(2500) NULL, constraint JOB_INST_EXEC_FK foreign key (JOB_INSTANCE_ID) references BATCH_JOB_INSTANCE(JOB_INSTANCE_ID) ) ENGINE=InnoDB 18:46:45.087 [main] DEBUG o.m.jdbc.client.impl.StandardClient - execute query: CREATE TABLE BATCH_JOB_EXECUTION_PARAMS ( JOB_EXECUTION_ID BIGINT NOT NULL , TYPE_CD VARCHAR(6) NOT NULL , KEY_NAME VARCHAR(100) NOT NULL , STRING_VAL VARCHAR(250) , DATE_VAL DATETIME(6) DEFAULT NULL , LONG_VAL BIGINT , DOUBLE_VAL DOUBLE PRECISION , IDENTIFYING CHAR(1) NOT NULL , constraint JOB_EXEC_PARAMS_FK foreign key (JOB_EXECUTION_ID) references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID) ) ENGINE=InnoDB 18:46:46.209 [main] DEBUG o.m.jdbc.client.impl.StandardClient - execute query: CREATE TABLE BATCH_STEP_EXECUTION ( STEP_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY , VERSION BIGINT NOT NULL, STEP_NAME VARCHAR(100) NOT NULL, JOB_EXECUTION_ID BIGINT NOT NULL, START_TIME DATETIME(6) NOT NULL , END_TIME DATETIME(6) DEFAULT NULL , STATUS VARCHAR(10) , COMMIT_COUNT BIGINT , READ_COUNT BIGINT , FILTER_COUNT BIGINT , WRITE_COUNT BIGINT , READ_SKIP_COUNT BIGINT , WRITE_SKIP_COUNT BIGINT , PROCESS_SKIP_COUNT BIGINT , ROLLBACK_COUNT BIGINT , EXIT_CODE VARCHAR(2500) , EXIT_MESSAGE VARCHAR(2500) , LAST_UPDATED DATETIME(6), constraint JOB_EXEC_STEP_FK foreign key (JOB_EXECUTION_ID) references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID) ) ENGINE=InnoDB 18:46:47.172 [main] DEBUG o.m.jdbc.client.impl.StandardClient -…

在启动整个spring boot项目时,出现错误: Could not resolve placeholder 原因:没有指定好配置文件,因为src/main/resources下有多个配置文件,例如application-dev.properties, boss.properties等。 解决办法: 在application.properties中加入 spring.profiles.active=@env@ 很多时候,我们项目在开发环境和生成环境的环境配置是不一样的,例如,数据库配置,在开发的时候,我们一般用测试数据库,而在生产环境的时候,我们是用正式的数据,这时候,我们可以利用profile在不同的环境下配置用不同的配置文件或者不同的配置 spring boot允许你通过命名约定按照一定的格式(application-{profile}.properties来定义多个配置文件,然后通过在application.properyies通过spring.profiles.active来具体激活一个或者多个配置文件,如果没有没有指定任何profile的配置文件的话,spring boot默认会启动application-default.properties。 https://www.ossez.com/t/spring-boot-could-not-resolve-placeholder/14140
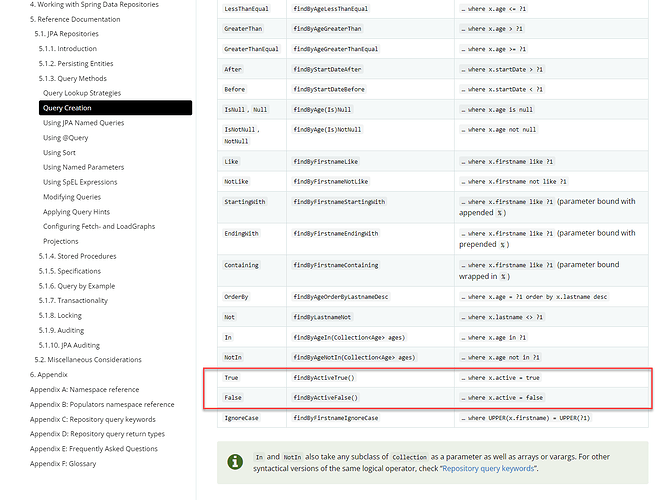
根据官方的文档说明:Spring Data JPA - Reference Documentation 可以在查询的参数后面添加 True 或 False 来进行查询。 例如,如果需要对下面的参数进行查询: True findByActiveTrue() … where x.active = true False findByActiveFalse() … where x.active = false 那么我们在查询的接口上可以使用: @Query public Iterable<Entity> findByEnabledTrue(); 来完成查询。 https://www.ossez.com/t/spring-jpa/14137