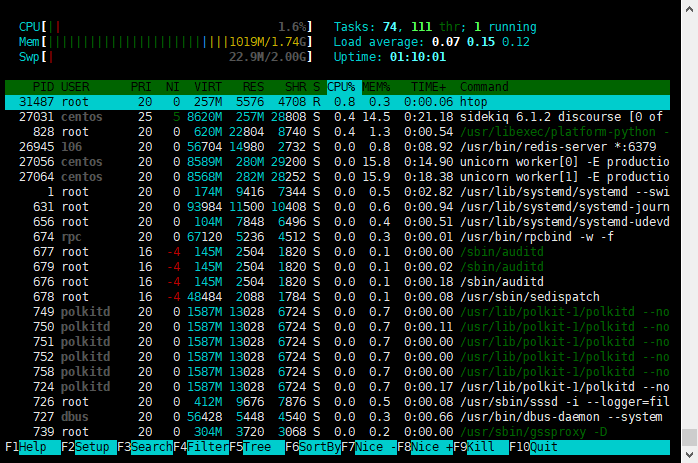
如果你安装使用的是 CentOS 的话,你可能没有办法直接安装 htop。 你会得到下面的信息: [root@vps-f2a02f66 discourse]# htop -bash: htop: command not found 解决办法 你可以将 RHEL 添加到你的仓库中。 运行下面的命令: yum install https://dl.fedoraproject.org/pub/epel/epel-release-latest-8.noarch.rpm 上面的命令将会添加 RHEL 到仓库中,在过程中你需要输入 Y 来同意校验。 在完成上面的操作后,再执行 yum install htop 来执行安装。 在完整完成后,可使用 htop 命令来查看系统的运行情况。 如果你可以看到上面的界面,则表明 htop 已经安装成功。

在更新或者安装 docker 容器的时候,提示下面的错误: Problem: package docker-ce-3:19.03.13-3.el7.x86_64 requires containerd.io >= 1.2.2-3 上面的问题如何解决。 解决 根据提示的内容,上面已经说得比较明确了。 就是需要使用 containerd.io 的版本要升级下。 你可以访问 docker 官方的链接有关 CentOS 的安装部分: Docker Documentation – 1 Oct 20 Install Docker Engine on CentOS To get started with Docker Engine on CentOS, make sure you meet the prerequisites, then install Docker. Prerequisites OS requirements To install Docker Engine, you need a maintained version of... 首先你需要设置仓库: sudo yum install -y yum-utils sudo yum-config-manager \ --add-repo \ https://download.docker.com/linux/centos/docker-ce.repo 然后执行命令 sudo yum install docker-ce docker-ce-cli containerd.io 就可以解决上面的问题了。 https://www.ossez.com/t/centos-8-docker-containerd-io-1-2-2-3/548
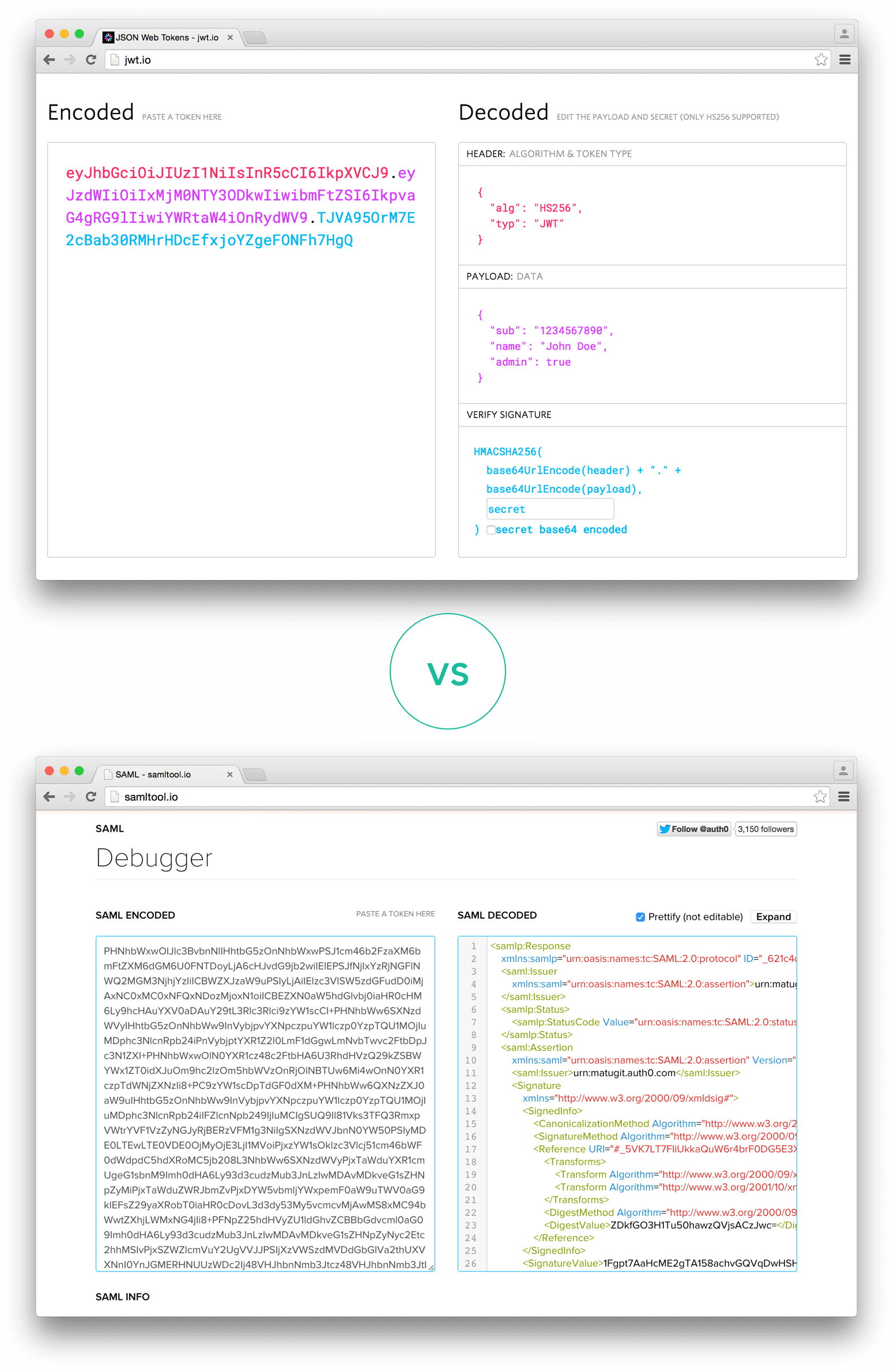
让我们讨论下 JSON Web Tokens (JWT) 针对 Simple Web Tokens (SWT) 和 Security Assertion Markup Language Tokens (SAML) 而言有什么优势吧。 相对 XML 来说,JSON 格式更加简洁,对 JSON 格式进行编码后的数据量更小,这就使得 JWT 相对 SAML 来说显得更加小巧,这使得 JWT 更加容易能够在 HTTP 和 HTML 环境之间传递数据。 在安全性上面,SWT 只能使用通过 HMAC 算法的对称方式签名。JWT 和 SAML 都可以使用基于 X.509 认证的公钥/私钥 密钥对的方式进行加密和解密。相比针对 JSON 格式的签名,针对XML 的数字签名更加容易导入安全漏洞。 在 JSON 格式的处理上,当前几乎所有的语言都能够支持和进行解析,这是因为 JSON 格式的数据更加容易映射到数据对象中。XML 则没有针对文本到对象的映射支持。这就导致了相对 SAML 来说,JWT 的处理更加容易。 在使用方面,JWT 已经被大量的在互联网上面取得了应用,针对多平台的使用上,JSON 格式在客户端上面更加容易被使用,尤其是针对移动平台。 针对 JSON 和 SAML 数据格式的内容对比,请参考下面的图片: 从上面的图片的对比上,我们可以看到基于 JSON 格式的内容更少,表达性更好。 如果你希望了解更多有关 JSON Web Tokens 的使用,并且打算开始在你的系统中应用这种格式,请参考由 Auth0 官方提供的介绍和文档,访问链接是:http://auth0.com/learn/json-web-tokens。 https://www.ossez.com/t/json-web-tokens/537

不需要。直接修改环境变量就可以了。 根据使用的操作系统不同,不同的操作系统可能有所不同。 Windows 的话 PATH 看一下 指向的 JDK 是哪个路径。 如果你要CMD 查看的话,你需要关闭 CMD 窗口,然后重新打开。
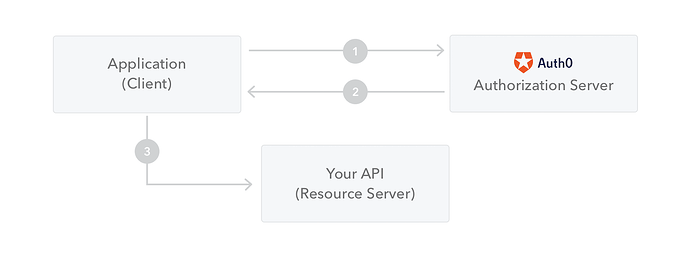
在用户权限校验的过程中,一个用户如果使用授权信息成功登录后,一个 JSON Web Token 将会返回给用户端。 因为返回的令牌包含有授权信息,应用程序应小心保存这些授权信息,以避免不必要的安全问题。你的应用程序在不需要授权信息的时候,应用程序不应该保留授权成功后返回的令牌。 应用程序也不应该将这些敏感信息保存在浏览器中,因为这样会更加容易导致信息泄漏,请参考链接:https://cheatsheetseries.owasp.org/cheatsheets/HTML5_Security_Cheat_Sheet.html#local-storage 中的内容。 在任何时候,如果用户希望访问一个受保护的资源或者路由的时候,用户应该在访问请求中包含 JWT 令牌。通常这个令牌是存储在 HTTP 请求的头部信息,一般会使用 Authorization 字段,使用 Bearer 模式。 Http 头部发送给后台所包含的内容看起来如下所示: Authorization: Bearer <token> 在某些情况下,可以使用无状态的授权机制。服务器上受保护的路由将会检查随着访问提交的 JWT 令牌。如果令牌是有效的,用户将会被允许访问特定的资源。 如果 JWT 令牌中包含有必要的信息,服务器的服务端将不需要再次对数据库进行查询以加快访问速度。当然,不是所有的时候都可以这样进行处理。 当令牌随着头部中的 Authorization 信息一同发送,那么我们不需要使用 cookies,因此跨域访问(Cross-Origin Resource Sharing (CORS))也不应该成为一个问题。 下面的示例图展示了JWT 是如何被获得的,同时也展示了 JWT 是如何被使用来访问服务器 API 的。 1. 应用程序或者客户端,通过对授权服务器的访问来获得授权。这个可能有不同的授权模式。例如,通常我们可以使用 OpenID Connect 提供的标准的授权地址来进行授权,请参考链接:http://openid.net/connect/。通常来说一个标准的授权地址为 /oauth/authorize,并且使用下面类似的标准授权流程,请参考链接:http://openid.net/specs/openid-connect-core-1_0.html#CodeFlowAuth 中的内容。 2. 当授权完成后,授权服务器将会返回访问令牌(access token)给应用。 3. 应用使用获得的令牌来访问收到保护的资源(例如 API)等。 需要注意的是,通过使用了签名的令牌,尽管用户可能没有办法对使用的令牌进行修改,但是令牌中包含的所有信息将会暴露给用户或者其他的应用。因此,你不应该在你的令牌中存储密钥或者任何的敏感信息。 https://www.ossez.com/t/json-web-tokens/532
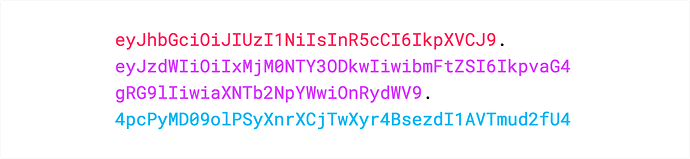
JSON Web Tokens 由使用 (.) 分开的 3 个部分组成的,这 3 个部分分别是: 头部(Header) 负载(Payload) 签名(Signature) 正是因为上面的组织形式,因此一个 JWT 通常看起如下面的表现形式。 xxxxx.yyyyy.zzzzz 让我们针对上面的形式来具体的分析下。 头部(Header) 在头部的数据中 通常 包含有 2 部分的内容:token 的类型,这里使用的是字符 JWT,和使用的的签名加密算法,例如 SHA256 或者 RSA。 例如下面的格式: { "alg": "HS256", "typ": "JWT" } 然后,将上面的 JSON 数据格式使用 Base64Url 算法进行哈希,这样你就得到了 JWT 的第一部分。 负载(Payload) JWT 的第二部分为负载,在负载中是由一些 claims 组成的。 Claims 是一些实体(通常指用户)和其他的一一些信息。 有下面 3 种类型的 claims registered, public 和 private 。 Registered claims:这些 claims 是预先定义的,这些配置的内容不是必须的但是是推荐使用的,因此提供了一系列约定俗成使用的。比如:iss(issuer), exp(expiration time), sub(subject),aud(audience)和其他的一些更多的配置。 请注意,这些约定俗成的配置只有 3 个字符,以便于压缩数据量。 Public claims:这些数据可以由使用 JWT 的用户自由去定义,但是为了避免冲突,你需要参考在 IANA JSON Web Token Registry 中对它们进行定义,或者将这些内容定义为 URI,并且需要避免可能出现的冲突。 Private claims:这些内容是自定义的内容,这部分的内容被用于在数据传输端间进行转换的数据。这些数据是没有在 registered 和 public 中间没有定义的内容。 一个示例的负载: { "sub": "1234567890", "name": "John Doe", "admin": true } 负载(payload) 中的数据也是经过 Base64Url 进行加密的,这部分加密的内容组成了 JWT 的第二部分。 请注意:针对令牌这部分的签名已经被防范篡改。但是这部分还是可以被解密的,因此请不要将任何密钥放到这部分的数据中,除非你的密钥是已经加密过的密钥。 签名(Signature) 为了创建一个加密部分,你需要有已经编码过的头部和负载,然后你还需要一个密钥(secret)和一个已经在头部中指定的加密算法来进行签名。 例如,如果你希望使用 HMAC SHA256 算法来进行签名,那么这个算法中使用的数据为: HMACSHA256( base64UrlEncode(header) + "." + base64UrlEncode(payload), secret) 签名的作用主要用于校验传输的令牌(Token)数据没有在过程中被篡改。 如果你的令牌是通过私有密钥进行签名的,那么也可以对 JWT 进行校验,以确定 JWT 的发送方使用是合法的签名。 将所有内容整合在一起 将这个 3 部分的内容使用 Base64-URL 编码后整合到一起,将每部分的数据直接使用 点号(.) 进行分隔,以确保令牌数据能够比较容易的在网络 HTTP 和 HTML 环境中进行传输。 针对使用 XML 的令牌,例如 SAML 来说,JWT 显得更加简洁和高效。 下面是使用了头部信息,负载信息和数字签名然后组合到一起的一个 JWT 令牌示例: 如果你想使用 JWT,并且对一个已有的 JWT 令牌进行解密的话,你可以使用 https://jwt.io/#debugger-io 网站上提供的工具来对 JWT 字符串进行解密,校验和生产一个 JWT 令牌。 https://www.ossez.com/t/json-web-token/531

有关本文档的快速链接,请参考页面提示。 链接名称 URL 内容说明 GitHub MD 源代文件 https://github.com/cwiki-us-docs/cwikius-docs/blob/master/jwt/README.md 将本页面中的内容转换为 MD 文件的手册,并存于 Github 上面 Docsify 转换后的手册 https://cwiki-us-docs.github.io/cwikius-docs/#/jwt/README 将 MD 文件使用 Docsify 转换后的手册链接地址 问题讨论和社区 https://www.ossez.com/tag/jwt 请访问使用 JWT 标签 CWIKI.US 页面链接 https://www.cwiki.us/display/CWIKIUSDOCS/JWT+-+JSON+Web+Token Confluence 平台的原始翻译文件更新地址 什么是 JSON Web Token(JWT)? JSON Web Token (JWT) 作为一个开放的标准 (RFC 7519) 定义了一种简洁自包含的方法用于通信双方之间以 JSON 对象的形式安全的传递信息。因为有数字签名,所以这些通信的信息能够被校验和信任。 JWT 可以使用秘钥(secret)进行签名 (使用 HMAC 算法) 或使用 RSA 或 ECDSA 算法的公钥/私钥对(public/private key)。 尽管 JWT 可以在通讯的双方之间通过提供秘钥(secret)来进行签名,我们将会更多关注 **已签名(signed)**的 token。 通过签名的令牌可以验证其中数据的 完整性(integrity) ,而加密的令牌可以针对其他方 隐藏(hide) 申明。 当令牌(token)使用 公钥/私钥对(public/private key)进行签名的时候,只有持有私钥进行签名的一方是进行签名的。 关键术语的中英文对照 token - 令牌 secret - 秘钥 signature - 签名 claims - 要求或者数据 https://www.ossez.com/t/json-web-token-jwt/528
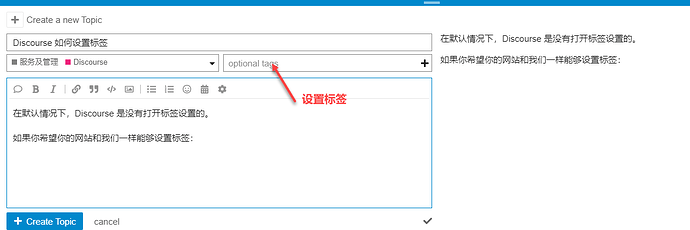
在默认情况下,Discourse 是没有打开标签设置的。 如果你希望你的网站和我们一样能够设置标签。 如何设置标签 登录 Discourse 的后台,选择 settings 标签,然后搜索 tags。 在搜索结果中,选择启用标签,然后刷新前台页面,你就可以选择使用标签了。 在上图中你可以看到已经启用的标签,你可以在你的平台上启用不同的标签。 https://www.ossez.com/t/discourse/530
JumpCloud 是一个基于云的 LDAP 服务。 如果你的项目小组成员在 10 个或者 10 个以下的话,你可以免费使用 JumpCloud 服务器。 这篇文章假设的是你已经设置好了 JumpCloud 的云服务,并且已经注册了 JumpCloud 的管理员和后台访问权限。同时你希望使用 Apache Directory Studio 来连接 JumpCloud 提供的云 LDAP 服务。 登录 JumpCloud 的管理员后台 管理员后台的地址为:https://console.jumpcloud.com/login 在这里你需要输入你管理员的账号和密码,如果你是用户的话,你需要使用你用户的账号和密码在用户前端进行登录。 登录成功后,你可以看到所有的用户列表。 如果是管理员的话,你可以选择你管理员的用户名称。 然后找到 LDAP 的 DN 名称。 这个就是你 JumpCloud 管理员的 DN,你需要将这一长串字符串拷贝下来。 在你使用 Apache Directory Studio 进行登录的时候,你需要这个 DN 才能够进行登录。 Apache Directory Studio 创建连接 登录 Apache Directory Studio ,然后可以在左侧的下面配置连接。 配置 JumpCloud 的网络参数。 Hostname: ldap.jumpcloud.com Port: 389 然后可以检查网络参数。 配置 JumpCloud 的授权 在 DN 粘贴上面我们提到的需要你保存的 DN。 在密码部分输入你登录 JumpCloud 控制台的密码。 在配置完成后,可以单击检查授权来查看你的用户信息是否正确。 如果你的配置是正确的话,你将会看到授权已经成功的提示,这个时候你就可以应用并且关闭连接配置界面了。 浏览目录 在右下角双击连接,然后将会在左上显示一个 DIT。 如果你双击 DIT 的话,你可能看不到任何你存储到 JumpCloud 上面的用户,这是因为你 DN 的 Base DN 路径不正确。 其实也不能说不正确,因为你的用户授权的 CN 比较低,你需要返回到上一级。 右键,然后在弹出的对话框中选择 Go to Dn 然后在弹出的对话框中输入: o=*********************,dc=jumpcloud,dc=com 其实就是在上面拷贝的 DN,但是这个 DN 需要去掉 cn 部分的内容。 这个操作的目的就是在授权成功后,返回到 上一级的 DN,因为你的用户和用户组信息都会在上一级的 DN 上面。 然后你就可以在这里查看用户和用户组的信息了。 这里能够查看到的信息应该是与 JumpCloud 上面配置的用户和用户组信息对应的。 至此,你的 Apache Directory Studio 和 JumpCloud 就已经完全配置成功并且建立连接了。 https://www.ossez.com/t/apache-directory-studio-jumpcloud/527

在编译的时候有下面的警告提示: Deprecated Gradle features were used in this build, making it incompatible with Gradle 7.0. Use ‘–warning-mode all’ to show the individual deprecation warnings. See https://docs.gradle.org/6.3/userguide/command_line_interface.html#sec:command_line_warnings CONFIGURE SUCCESSFUL in 14s 如何进行查看和操作? 解决办法 其实这是一个比较简单的问题。 上面的提示信息已经告诉你怎么运行了。 你可以运行命令 gradlew --warning-mode all 在输出中,你可以看到下面的信息 Configure project : The compile configuration has been deprecated for dependency declaration. This will fail with an error in Gradle 7.0. Please use the implementation configuration instead. Consult the upgrading guide for further information: https:// docs.gradle.org/6.3/userguide/upgrading_version_5.html#dependencies_should_no_longer_be_declared_using_the_compile_and_runtime_configurations at build_45djmc9u5bi478od1utks361r$_run_closure1$_closure8.doCall(C:\WorkDir\Ossez-Com\USData\Source-Code\covid-19\build.gradle:53) (Run with --stacktrace to get the full stack trace of this deprecation warning.) 上面的内容已经很明确的告诉你存在兼容性问题的地方在哪里。 根据提示的内容进行修改就可以了。 上面的说明是: Please use the implementation configuration instead 你使用 implementation 配置就行了。