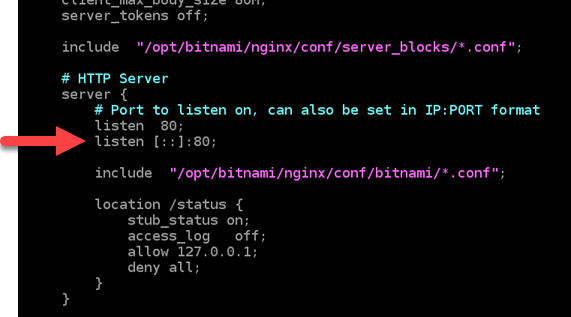
其实很简单的配置就可以了: server { listen 80; listen [::]:80; return ^ 301 https://$host$request_uri; } 因为 IPv6 的表示方式和 IPv4 不一样,所以你需要新添加一行 listen [::]:80; 就可以了。 然后你在你的 DNS 上配置 IPv6,你的服务器也是可以正常解析地址的。 https://www.ossez.com/t/nginx-ipv4-ipv6/14031

我们都知道 Strings 在 Java 中使用 char[] 数组来实现的。 每一个 char[] 数组中的元素将会使用 2 个字节(byte)的存储空间,这是因为 Java 最初的实现使用 UTF-16 字符集。 如果你不需要存储其他语言,你的语言只有英文,或者 ASCII 码就可以满足的情况下,Java String 使用的 char[] 数组中存储的字符元素还是会使用 UTF-16 字符集,那么就会导致存储一个字符的时候,我们使用了 2 字节,16 位。但是,因为我们又全是因为,那么存储的这个字符的前 8 位全部都会为 0。 因为 ASCII 使用单字节存储,这明显是一个存储空间的浪费。 实际上,很多字符存储都需要使用 2 字节,比如 UTF-8,比如 GBK,但是针对因为和 拉丁文 LATIN-1 使用 1 个字节的存储就够了,很显然这里有一个可以改进的空间。 在 JDK 9 之前,Java 不管什么字符都一股脑的使用 2 字节存储,在 JDK 9 以后,Java 对这里进行了改进。 同时我们知道 Java 是使用 String Pool 来存储的,String Pool 通常使用了 JVM 的 heap 内存空间,Heap 内存空间又是 JVM 垃圾清理程序活动的地方。 在老的设计中,String 占用了 2 个字节,但是很多时候可能用不到,如果我们对这里进行了改进的话,我们也能提高垃圾清理程序的工作量。 显然这个是需要重新考虑的问题。 在本页面中,我们将会讨论在 JDK 6 中使用的 Java String 的压缩选项和在 JDK 9 中使用的新的方法。 这 2 种方法主要目的就是为了降低 String 在 JVM 中内存消耗,提供空间利用率。 https://www.ossez.com/t/java-9-string/14024

当你设置好 Nginx 服务器后,并且你也相信你的虚拟主机都设置好了。 但是你就是老看到一个 403 的错误,这个绝大部分情况是因为 SELinux 造成的。 解决办法 首先运行命令: setenforce 1 然后查看下你的程序能不能通过 URL 正常的访问。 如果能够正常访问的话,这个就铁定是 SELinux 的问题了。 你还可以运行下面的命令,将 http 加入到信任的列表中: semanage permissive -a httpd_t 在完成上面的设置后,可以重启服务器,让你的配置生效。 https://www.ossez.com/t/nginx-403/14029
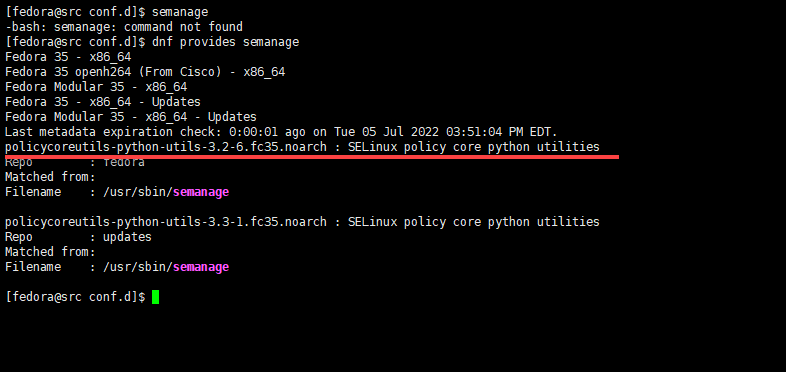
Semanage是 用于配置SELinux策略某些元素而无需修改或重新编译策略源的工具。 这包括将Linux用户名映射到SELinux 用户身份以及对象(如网络端口,接口和主机)的安全上下文映射。 Semanage是 用于配置SELinux 策略某些元素而无需修改或重新编译策略源的工具。 如果没有 Semanage,你要对 SELinux 配置的话就比较麻烦,但是 SELinux 又是现在 Linux 的标配了,所以这个包也就变得很重要了。 检查要安装的包 有时候,你可能不知道要安装的包是什么。 运行下面的命令: dnf provides semanage 然后你可以看到下面的输出,在下面的输出中,你会看到一个名为: policycoreutils-python-utils-3.2-1.fc34.noarch 的包名称以及版本号。 在安装的时候是不需要提供版本号的。 安装 当你找到包的名称后,运行命令: sudo dnf install policycoreutils-python-utils 就可以了,在这里你不需要提供版本号。 dnf 会自动帮你安装最新的包。 校验安装 输入命令 semanage -h 如果你能够看到下面的输出的话,就说明你的安装已经成功了。 [fedora@src conf.d]$ semanage -h usage: semanage [-h] {import,export,login,user,port,ibpkey,ibendport,interface,module,node,fcontext,boolean,permissive,dontaudit} ... semanage is used to configure certain elements of SELinux policy with-out requiring modification to or recompilation from policy source. positional arguments: {import,export,login,user,port,ibpkey,ibendport,interface,module,node,fcontext,boolean,permissive,dontaudit} import Import local customizations export Output local customizations login Manage login mappings between linux users and SELinux confined users user Manage SELinux confined users (Roles and levels for an SELinux user) port Manage network port type definitions ibpkey Manage infiniband ibpkey type definitions ibendport Manage infiniband end port type definitions interface Manage network interface type definitions module Manage SELinux policy modules node Manage network node type definitions fcontext Manage file context mapping definitions boolean Manage booleans to selectively enable functionality permissive Manage process type enforcement mode dontaudit Disable/Enable dontaudit rules in policy options: -h, --help show this help message and exit 上面提供了这个命令可以使用的帮助。 至此,配置已经完成了。 https://www.ossez.com/t/fedora-semanage/14028
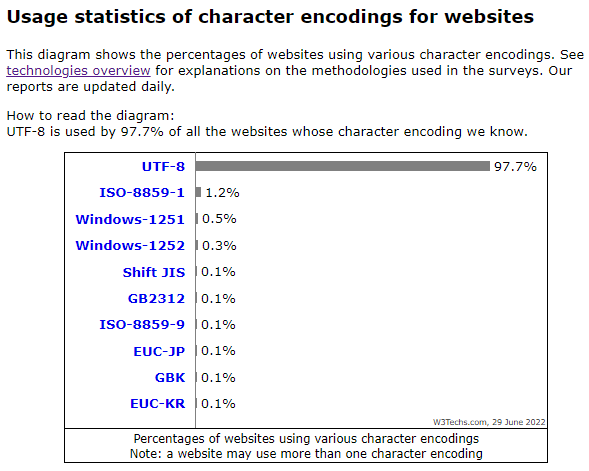
乱码是所有程序员都经历过的噩梦。 拯救你生命的只有 UTF-8。 如果你不知道用什么字符集,用 UTF-8,如果没有强制要求,也用 UTF-8,相信我,没错的。 从上面的网页使用的编码就知道为什么了。如果你的公司还在使用 ISO-8895-1 的话,你可以好好鄙视下,说明这公司负责技术的不行嘛。 如果你公司是中文公司,被强制使用 GBK 或者 GB18030,你就不要鄙视了,因为使用 GB 字符集是在中国大陆销售的软件的强制标准,但是还使用 GB 2312 的话,你也可以鄙视下了。 欧美的编码 欧美常常使用的编码是不适合中文使用的,换句话说就是你写的代码没有办法接受中文的输入也没有办法存储中文,当然也没有办法存储日韩文字了。 ASCII 编码 (American Standand Code for InformationInterchange) 的缩写 ASCII 码是计算机最开始支持的基于拉丁字母的编码,一个字符用一个字节表示,只用了低 7 位,最高位为 0,因此总共有 128 个ASCII码,范围为 0~127。 这个编码应该是大学计算机课程的第一节课,就是要学习 ASCII 编码。 这个字符集简单来说就是只能用于英文,字符集太小,啥都存不下。 ISO-8859-1 编码 ISO -8859-1编码 是单字节编码 ,向下兼容ASCII,其编码*范围是0x00-0xFF,0x00-0x7F之间完全和ASCII一致,0x80-0x9F之间是控制字符,0xA0-0xFF之间是文字符号。 因为 ASCII 字符集实在太小了,现在就有了 ISO-8859-1。 对我们来说这个字符集的最大问题就是不能支持中文,韩语,日文,在欧美国家用用还行。 但是很多软件默认都使用 ISO-8859-1,欧美国家的程序员又没有太多字符集的需求,因此很有可能会默认就使用这个字符集,所以你也可以吐槽下。 中文字符集 中文字符集就是我们常用的 GB 字符集了。 GB是 国标 两字的拼音首字,2312 是标准序号。GB 有 3 个版本,按照字符集的大小排序,其实也是按照发布时间排序。 GB2312 最早的中文字符集,和 ASCII 字符集一样,字符集太小,很多汉字打不出来,异体字也打不出来。 GB2312 规定对收录的每个字符采用两个字节表示。 GBK 即汉字国标扩展码。 GBK编码,是对GB2312编码的扩展,因此完全兼容GB2312-80标准。GBK编码依然采用双字节编码方案,其编码范围:8140-FEFE,剔除xx7F码位,共23940个码位。共收录汉字和图形符号21886个,其中汉字(包括部首和构件)21003个,图形符号883个。GBK编码支持国际标准ISO/IEC10646-1和国家标准GB13000-1中的全部中日韩汉字,并包含了BIG5编码中的所有汉字。GBK编码方案于1995年12月15日正式发布,这一版的GBK规范为1.0版。 Windows 95 系统就是以GBK为内码,又由于GBK同时也涵盖了Unicode 所有CJK汉字,所以也可以和Unicode 做一一对应。 从 2000 年以后的程序设计相关,如果是中文的话,基本上都会使用 GBK 字符集了,已经不怎么使用 GB2312 字符集了。 因为 GBK 的字符存储得更多,生僻字也可以显示了。 GB18030 2000年3月17日发布的汉字编码国家标准GB18030编码,是对GBK编码的扩充,覆盖中文、日文、朝鲜语和中国少数民族文字,其中收录27484个汉字。 GB18030字符集采用单字节、双字节和四字节三种方式对字符编码。兼容GBK和GB2312字符集。 它完全兼容ASCII码与GBK码。 GB18030 是对 GBK 编码的进一步扩充,字符集更大,可以存储的汉字更多。 但是针对 Web 开发来说,其实我们也用不到那么多汉字,所以现在很多网站还是在使用 GBK 的编码。 BIG5 这个简称就是繁体中文使用的,主要在台湾,香港地区使用。 BIG5编码又称大五码,是繁体中文字符集编码标准,共收录13060个中文字,其中有二字为重复编码。 BIG5重复地收录了两个相同的字:“兀、兀”(A461及C94A)、“嗀、嗀”(DCD1及DDFC)。 适用于台湾和香港地区的繁体中文系统软件等。不过由于编码本身存在的问题,已经基本改用 Unicode 编码了。 BIG5 目前已经不怎么使用了,我们在这里列出来就是想说明下曾经还有一个这样的编码而已。 Unicode 你的救星来了。 Unicode(统一码、万国码、单一码、标准万国码)编码就是为了表达任意语言的任意字符而设计的。 目前的情况是大部分程序,数据库,通讯协议都会使用 UTF-8 编码。 使用 UTF-8 编码能够适配所有的字符集并且不容易出现乱码问题。 如果你不知道你要什么编码,用 UTF-8 编码就没错的了。 Java 中 String 字符串的存储是使用 UTF-16 编码存储的,在 JDK 9+ 以后的版本,Java 对 String 的存储进行了压缩以增加空间使用率。 如果你是早期的程序员,你一定经历过转码的痛苦,不要想太多,UTF-8 才是你的真爱。 https://www.ossez.com/t/topic/14022
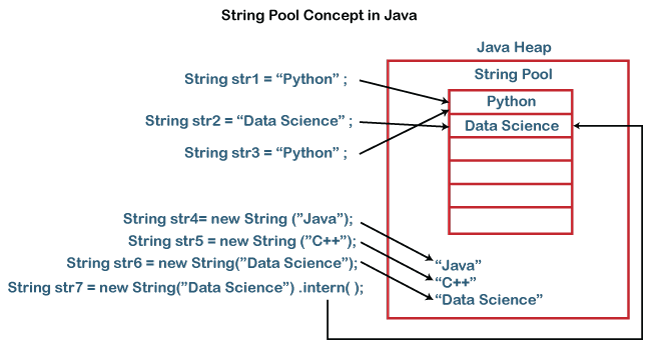
在 Java 中 String 对象是我们最常用的对象。 在本文章中,我们主要对 String 对象使用的 String Pool 进行一些简单的介绍。 Java 定义 String 后,String 是存储在 String Pool 中的,以便于加快字符串的访问和处理。 正是有这个方面的访问需求,JVM 为 String 对象在内存中特地开辟了一个存储区域来加快对 String 对象的访问,这个特定的内存区域就是我们说的 String Pool 了。 字符串引用(String Interning) 我们都知道 Strings 在 Java 中是不可变的( immutable),因此 JVM 可以通过访问这个字符串的引用,或者我们可以借用指针的这个概念来访问 String 字符串。 通过指针访问字符串值的这个过程就可以称为引用(interning)。 当我们在内存中创建一个字符串的时候,JVM 将会根据你创建字符串的值在内存中进行查找有没有和你创建值相同的 String 对象已经被创建了。 如果,JVM 找到了这个对象的话,JVM 就将会为你创建的对象返回已经存在 String 的地址的引用,而不会继续申请新的内存空间,以便于提高内存的利用率。 如果,JVM 没有找到与创建对象相同的值的话,JVM 将会申请内存空间并且创建这个 String 对象,然后将新创建的这个 String 的对象进行返回,这个过程就称为引用(interned)。 让我们使用下面的方法进行验证: @Test public void whenCreatingConstantStrings_thenTheirAddressesAreEqual() { String constantString1 = "HoneyMoose"; String constantString2 = "HoneyMoose"; assertThat(constantString1).isSameAs(constantString2); } 上面的方法将会通过,原因是 constantString2 在创建的时候,将会得到的是 constantString1 内存地址的引用。 因此上面 2 个字符串是完全相同的。 String 构造方法中的内存分配 因为构造 String 对象有几种不同的方法,我们可以通过直接赋值的方式构造 String 对象,我们也可以通过 new 的方式来构造一个 String 对象。 在这里我们需要说如果使用 new 这个关键字来构造的 String对象。 简单来说,如果你使用了 new 这个关键字来构造 String 对象的话,不管 String 对象中的值是不是相同,JVM 都会为构造的对象开辟存储空间,这个存储空间在 JVM 的 heap 中。 因此每个使用 new 构造的 String 对象都会有自己的内存地址。 让我们来看看下面的代码: @Test public void whenCreatingStringsWithTheNewOperator_thenTheirAddressesAreDifferent() { String newString1 = new String("HoneyMoose"); String newString2 = new String("HoneyMoose"); assertThat(newString1).isNotSameAs(newString2); logger.info("newString1 Address: {}", System.identityHashCode(newString1)); logger.info("newString2 Address: {}", System.identityHashCode(newString2)); } 上面的代码将会输出: 16:03:38.916 [main] INFO c.o.stringpool.StringPoolUnitTest - newString1 Address: 429075478 16:03:38.919 [main] INFO c.o.stringpool.StringPoolUnitTest - newString2 Address: 1802066694 我们可以看到使用 new 以后的 String 的地址空间是不一样的。 String 文字(Literal)和 对象(Object) 当我们创建 String 对象的时候,如果使用 new() 的方式来创建一个 String 对象,JVM 将会每次都会在 heap 内存中为我们创建的 String 对象开辟一个存储空间来进行存储。 但是,如果我们使用赋值方式创建 String 对象的话,JVM 首先将会对我们赋的值到 String Pool 中进行查找,如果找到的话,就返回已经存在这个值的引用。 如果没有找到,就创建一个新的 String 对象并且返回这个创建对象的引用。 例如,我们如果使用赋值方式将值 “HoneyMoose” 创建的话,我们有可能会得到的是已经存在值的内存地址让我们能够来重新利用已经划分的内存,也有可能是一个全新的内存地址。 简单来说,这 2 种方式创建的 String 字符串都是 String 对象,唯一不同的是 new 操作每次都会给出新的地址,另外的操作则不能每次都是新的内存地址。 要解释这种情况,我们可以用一个数据基本面试问题的题目来进行解释,就是为什么使用 == 进行字符串比较的时候有时候会得到 False 的值。 因为,我们都知道 == 比较的是地址,而不是 String 中存储的值。 考察下面的代码: String first = "HoneyMoose"; String second = "HoneyMoose"; System.out.println(first == second); // True 在上面的初始化后比较中,我们会得到 True 的值,因为上面 2 个 String 的地址是相同的。 下面,我们再使用 new 关键字来创建 2 个新的 String 对象,然后再来比较 String 对象的引用: String third = new String("HoneyMoose"); String fourth = new String("HoneyMoose"); System.out.println(third == fourth); // False 相同的,我们使用 new 的方式来创建对象,我们可以看到上面创建的 String 的地址是不相同的。 因此使用 == 计算的结果是 False。 String fifth = "HoneyMoose"; String sixth = new String("HoneyMoose"); System.out.println(fifth == sixth); // False 通常来说,我们建议对 String 对象初始化的时候,使用文字方式对 String 对象初始化,这样的话我们能够让…

一直到 Java 8,Strings 在 Java 中使用字符数组进行存储的,同时使用的是 UTF-16 字符集,因此每一个字符将会使用 2 字节的内存。 从 Java 9 开始,Java 提供了一个叫做压缩字符(Compact Strings)的存储概念。 这个存储将会针对字符串使用 char[] 和 byte[] 中字符编码,这个将会与你需要存储的内容有关。 简单来说就是从 Java 9 开始,String 将会根据存储内容的不同来使用不同的存储格式,只会在必要的时候才会使用 UTF-16 编码,这种设计将会显著降低 String 对内存的使用,并且能够让来让垃圾清理程序(Garbage Collector)更有效率的工作。 简单来说就是 Java 9 以后对 String 字符串的存储进行了优化,针对不同字符集设置了不同的存储方案以降低空间的使用。 https://www.ossez.com/t/java-string-pool/14017

在 Java 6 中,我们唯一可以做的优化就是通过增加 PermGen 内存空间来提供更多的存储。 可以通过在 JVM 中使用参数来实现: -XX:MaxPermSize=1G 从 Java 7 开始,我们可以为 String Pool 指定更多的参数来扩展和减少 String Pool 的大小。 让我们来看看下面使用的 2 个参数: -XX:+PrintFlagsFinal -XX:+PrintStringTableStatistics 如果我们希望增加 String Pool 的 buckets 大小,我们可以使用 JVM 提供的 StringTableSize 参数选项: -XX:StringTableSize=4901 在 Java 7u40,默认的 String Pool 大小为 1009 buckets。 但是这个值在最近的一些 Java 版本更新中有了改变,从 7u40 到 Java 11 String Pool 的大小为 60013 buckets,在 Java 11 的后续版本中,这个值增加到了 65536 buckets。 需要注意的是,增加 String Pool 的大小将会增加 JVM 的内存消耗,但是也会降低在我们对 String 进行赋值的时候 JVM 对 String 表的处理时间。 https://www.ossez.com/t/java-string-pool/14017

手工修改引用的意思就是通过程序来手工修改 String 字符串使用的指针来获得我们需要的值。 手工修改指针的方法为 intern()。 手工修改 String 在 String 存储池中的引用,JVM 将会在我们需要的时候返回这个引用。 让我们来创建一个测试用例: String constantString = "interned HoneyMoose"; String newString = new String("interned HoneyMoose"); assertThat(constantString).isNotSameAs(newString); String internedString = newString.intern(); assertThat(constantString) .isSameAs(internedString); 上面代码中的第一次判断是不相同的,后来我们在创建一个新的 String 的对象的时候,使用了一个已经创建的 String 字符串的引用,那么我们的后面再进行判断的时候就是相同的了。 https://www.ossez.com/t/java-string-pool/14017

当我们创建 String 对象的时候,如果使用 new() 的方式来创建一个 String 对象,JVM 将会每次都会在 heap 内存中为我们创建的 String 对象开辟一个存储空间来进行存储。 但是,如果我们使用赋值方式创建 String 对象的话,JVM 首先将会对我们赋的值到 String Pool 中进行查找,如果找到的话,就返回已经存在这个值的引用。 如果没有找到,就创建一个新的 String 对象并且返回这个创建对象的引用。 例如,我们如果使用赋值方式将值 “HoneyMoose” 创建的话,我们有可能会得到的是已经存在值的内存地址让我们能够来重新利用已经划分的内存,也有可能是一个全新的内存地址。 简单来说,这 2 种方式创建的 String 字符串都是 String 对象,唯一不同的是 new 操作每次都会给出新的地址,另外的操作则不能每次都是新的内存地址。 要解释这种情况,我们可以用一个数据基本面试问题的题目来进行解释,就是为什么使用 == 进行字符串比较的时候有时候会得到 False 的值。 因为,我们都知道 == 比较的是地址,而不是 String 中存储的值。 考察下面的代码: String first = "HoneyMoose"; String second = "HoneyMoose"; System.out.println(first == second); // True 在上面的初始化后比较中,我们会得到 True 的值,因为上面 2 个 String 的地址是相同的。 下面,我们再使用 *new* 关键字来创建 2 个新的 String 对象,然后再来比较 String 对象的引用: String third = new String("HoneyMoose"); String fourth = new String("HoneyMoose"); System.out.println(third == fourth); // False 相同的,我们使用 new 的方式来创建对象,我们可以看到上面创建的 String 的地址是不相同的。 因此使用 == 计算的结果是 False。 String fifth = "HoneyMoose"; String sixth = new String("HoneyMoose"); System.out.println(fifth == sixth); // False 通常来说,我们建议对 String 对象初始化的时候,使用文字方式对 String 对象初始化,这样的话我们能够让 JVM 有机会对 String 初始化之前进行判断来完成内存优化而不需要重复创建相同的对象。 https://www.ossez.com/t/java-string-pool/14017