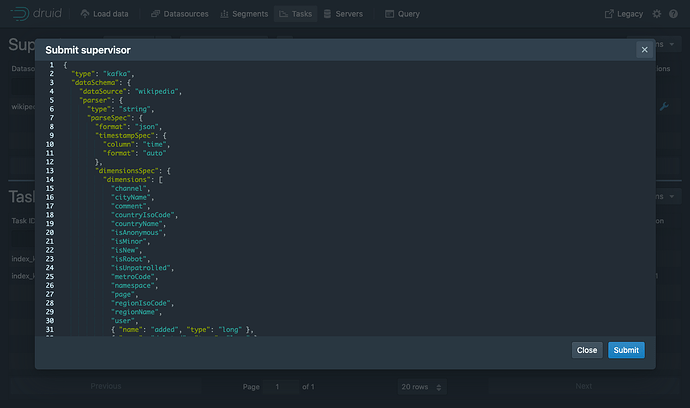
在控制台中,单击 Submit supervisor 来打开一个 supervisor 对话框。 请将下面的内容配置参数拷贝张贴到打开的对话框中,然后单击 Submit 提交。 { "type": "kafka", "spec" : { "dataSchema": { "dataSource": "wikipedia", "timestampSpec": { "column": "time", "format": "auto" }, "dimensionsSpec": { "dimensions": [ "channel", "cityName", "comment", "countryIsoCode", "countryName", "isAnonymous", "isMinor", "isNew", "isRobot", "isUnpatrolled", "metroCode", "namespace", "page", "regionIsoCode", "regionName", "user", { "name": "added", "type": "long" }, { "name": "deleted", "type": "long" }, { "name": "delta", "type": "long" } ] }, "metricsSpec" : [], "granularitySpec": { "type": "uniform", "segmentGranularity": "DAY", "queryGranularity": "NONE", "rollup": false } }, "tuningConfig": { "type": "kafka", "reportParseExceptions": false }, "ioConfig": { "topic": "wikipedia", "inputFormat": { "type": "json" }, "replicas": 2, "taskDuration": "PT10M", "completionTimeout": "PT20M", "consumerProperties": { "bootstrap.servers": "localhost:9092" } } } } 上面将会启动一个 supervisor,启动 supervisor 将会负责对任务进行管理,使用启动的任务来完成对数据的输入和从 Kafka 中获取数据。 https://www.ossez.com/t/druid-kafka-supervisor/13655
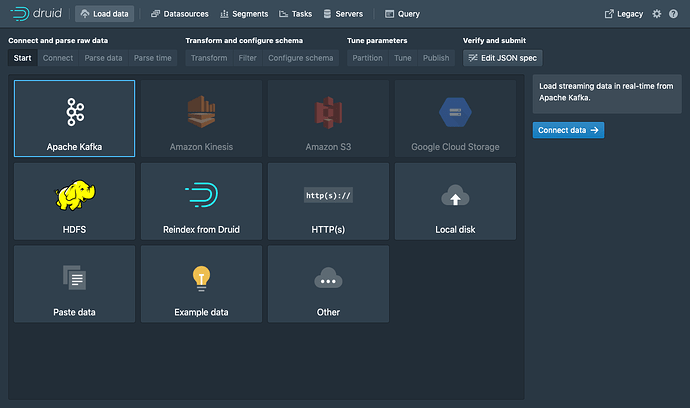
将数据载入到 Kafka 现在让我们为我们的主题运行一个生成器(producer),然后向主题中发送一些数据! 在你的 Druid 目录中,运行下面的命令: cd quickstart/tutorial gunzip -c wikiticker-2015-09-12-sampled.json.gz > wikiticker-2015-09-12-sampled.json 在你的 Kafka 的安装目录中,运行下面的命令。请将 {PATH_TO_DRUID} 替换为 Druid 的安装目录: export KAFKA_OPTS="-Dfile.encoding=UTF-8" ./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic wikipedia < {PATH_TO_DRUID}/quickstart/tutorial/wikiticker-2015-09-12-sampled.json 上面的控制台命令将会把示例消息载入到 Kafka 的 wikipedia 主题。 现在我们将会使用 Druid 的 Kafka 索引服务(indexing service)来将我们加载到 Kafka 中的消息导入到 Druid 中。 使用数据加载器(data loader)来加载数据 在 URL 中导航到 localhost:8888 页面,然后在控制台的顶部单击Load data。 选择 Apache Kafka 然后单击 Connect data。 输入 Kafka 的服务器地址为 localhost:9092 然后选择 wikipedia 为主题。 然后单击 Apply。请确定你在界面中看到的数据只正确的。 一旦数据被载入后,你可以单击按钮 “Next: Parse data” 来进行下一步的操作。 Druid 的数据加载器将会为需要加载的数据确定正确的处理器。 在本用例中,我们成功的确定了需要处理的数据格式为 json 格式。 你可以在本页面中选择不同的数据处理器,通过选择不同的数据处理器,能够帮你更好的了解 Druid 是如何帮助你处理数据的。 当 json 格式的数据处理器被选择后,单击 Next: Parse time 来进行入下一个界面,在这个界面中你需要确定 timestamp 主键字段的的列。 Druid 要求所有数据必须有一个 timestamp 的主键字段(这个主键字段被定义和存储在 __time)中。 如果你需要导入的数据没有时间字段的话,那么请选择 Constant value。 在我们现在的示例中,数据载入器确定 time 字段是唯一可以被用来作为数据时间字段的数据。 单击 Next: ... 2 次,来跳过 Transform 和 Filter 步骤。 针对本教程来说,你并不需要对导入时间进行换行,所以你不需要调整 转换(Transform) 和 过滤器(Filter) 的配置。 配置摘要(schema) 是你对 dimensions 和 metrics 在导入数据的时候配置的地方。 这个界面显示的是当我们对数据在 Druid 中进行导入的时候,数据是如何在 Druid 中进行存储和表现的。 因为我们提交的数据集非常小,因此我们可以关闭 回滚(rollup) ,Rollup 的开关将不会在这个时候显示来供你选择。 如果你对当前的配置满意的话,单击 Next 来进入 Partition 步骤。在这个步骤中你可以定义数据是如何在段中进行分区的。 在这一步中,你可以调整你的数据是如何在段中进行分配的。 因为当前的数据集是一个非常小的数据库,我们在这一步不需要进行调制。 单击 Next: Tune 来进入性能配置页面。 Tune 这一步中一个 非常重要 的参数是 Use earliest offset 设置为 True。 因为我们希望从流的开始来读取数据。 针对其他的配置,我们不需要进行修改,单击 Next: Publish 来进入 Publish 步骤。 让我们将数据源命名为 wikipedia-kafka。 最后,单击 Next 来查看你的配置。 等到这一步的时候,你就可以看到如何使用数据导入来创建一个数据导入规范。 你可以随意的通过页面中的导航返回到前面的页面中对配置进行调整。 简单来说你可以对特性目录进行编辑,来查看编辑后的配置是如何对前面的步骤产生影响的。 当你对所有的配置都满意并且觉得没有问题的时候,单击 提交(Submit). 现在你需要到界面下半部分的任务视图(task view)中来查看通过 supervisor 创建的任务。 任务视图(task view)是被设置为自动刷新的,请等候 supervisor 来运行一个任务。 当一个任务启动运行后,这个任务将会对数据进行处理后导入到 Druid 中。 在页面的顶部,请导航到 Datasources 视图。 当 wikipedia-kafka 数据源成功显示,这个数据源中的数据就可以进行查询了。 请注意: 如果数据源在经过一段时间的等待后还是没有数据的话,那么很有可能是你的 supervisor 没有设置从 Kafka 的开头读取流数据(Tune 步骤中的配置)。 在数据源完成所有的数据导入后,你可以进入 Query 视图,来针对导入的数据源来运行 SQL 查询。 因为我们当前导入的数据库很小,你可以直接运行SELECT * FROM "wikipedia-kafka" 查询来查看数据导入的结果。 请访问 query tutorial 页面中的内容来了解如何针对一个新载入的数据如何运行查询。 https://www.ossez.com/t/druid-kafka-kafka/13654
本教程演示了如何使用Druid的Kafka索引服务将数据从Kafka流加载到Apache Druid中。 假设你已经完成了 快速开始 页面中的内容或者下面页面中有关的内容,并且你的 Druid 实例已使用 micro-quickstart 配置在你的本地的计算机上运行了。 到目前,你还不需要加载任何数据。 下载和启动 Kafka Apache Kafka 是一个高吞吐量消息总线,可与 Druid 很好地配合使用。 在本指南中,我们将使用 Kafka 2.1.0 版本。下载 Kafka 后,在你的控制终端上运行下面的命令: curl -O https://archive.apache.org/dist/kafka/2.1.0/kafka_2.12-2.1.0.tgz tar -xzf kafka_2.12-2.1.0.tgz cd kafka_2.12-2.1.0 如果你需要启动 Kafka broker,你需要通过控制台运行下面的命令: ./bin/kafka-server-start.sh config/server.properties 使用下面的命令在 Kafka 中创建一个称为 wikipedia 的主题,这个主题就是你需要将消息数据发送到的主题: ./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic wikipedia 需要注意的是,我们假设你的 Kafka 和 Druid 的 ZooKeeper 使用的是同一套 ZK。 https://www.ossez.com/t/druid-kafka-kafka/13653

启动 Master 服务器 拷贝 Druid 的分发包和你修改过的配置到 Master 服务器上。 如果你已经在你的本地计算机上修改了配置,你可以使用 rsync 来进行拷贝。 rsync -az apache-druid-apache-druid-0.21.1/ MASTER_SERVER:apache-druid-apache-druid-0.21.1/ Master 没有 Zookeeper 的启动 从分发包的 root 节点中,运行下面的命令来启动 Master 服务器: bin/start-cluster-master-no-zk-server Master 有 Zookeeper 的启动 如果你计划在 Master 服务器上还同时运行 ZK 的话,首先需要更新 conf/zoo.cfg 中的配置来确定你如何运行 ZK。 然后你可以选择在启动 ZK 的同时启动 Master 服务器。 使用下面的命令行来进行启动: bin/start-cluster-master-with-zk-server 在生产环境中,我们推荐你部署 ZooKeeper 在独立的集群上面。 启动 Data 服务器 拷贝 Druid 的分发包和你修改过的配置到 Data 服务器上。 从分发包的 root 节点中,运行下面的命令来启动 Data 服务器: bin/start-cluster-data-server 如果需要的话,你还可以为你的数据服务器添加更多的节点。 针对集群环境中更加复杂的应用环境和需求,你可以将 Historicals 和 MiddleManagers 服务分开部署,然后分别进行扩容。 上面的这种分开部署方式,能够给代理 Druid 已经构建并且实现的 MiddleManager 自动扩容功能。 启动 Query 服务器 拷贝 Druid 的分发包和你修改过的配置到 Query 服务器上。 从分发包的 root 节点中,运行下面的命令来启动 Query 服务器: bin/start-cluster-query-server 针对你查询的负载情况,你可以为你的查询服务器增加更多的节点。 如果为你的查询服务器增加了更多的节点的话,请确定同时为你的 Historicals 服务增加更多的连接池。 请参考页面 basic cluster tuning guide 中描述的内容。 https://www.ossez.com/t/druid/13651
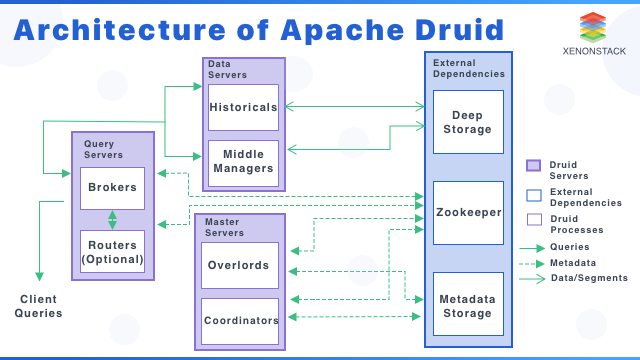
如果你的服务使用了防火墙,或者一些网络配置中限制了端口的访问的话。那么你需要在你的服务器上开放下面的端口,并运行数据进行访问: Master 服务器 1527 (Derby 原数据存储;如果你使用的是其他的数据库,例如 MySQL 或 PostgreSQL 的话就不需要) 2181 (ZooKeeper;如果你使用的是分布式 ZooKeeper 集群部署的话就不需要) 8081 (Coordinator 服务) 8090 (Overlord 服务) Data 服务器 8083 (Historical 服务) 8091, 8100–8199 (Druid Middle Manager 服务,如果你使用了比较高的 druid.worker.capacity 配置的话,那么你需要的端口可能会高于 8199) Query 服务器 8082 (Broker 服务) 8088 (Router 服务,如果使用的话) 在生产环境中,我们推荐你部署 ZooKeeper 和你的元数据存储到他们自己的硬件上(独立部署)。不要和 Master server 混合部署在一起。 https://www.ossez.com/t/druid/13650
从一个单独部署服务器上进行合并到集群的时候,需要对下面的一些配置进行调整。 Master 服务 如果你已经有一个已经存在并且独立运行的独立服务器部署的话,例如在页面 single-server deployment examples 中部署的服务器, 下面的这个示例将会帮助你将 Coordinator 和 Overlord 合并到一个进程上面 conf/druid/cluster/master/coordinator-overlord 下面的示例,显示例如如何同时合并 Coordinator 和 Overlord 进程。 你可以从已经部署的独立服务器上拷贝已经存在 coordinator-overlord 配置文件,并部署到 conf/druid/cluster/master/coordinator-overlord。 Data 服务 假设我们将要从一个 32 CPU 和 256GB 内存的独立服务器上进行合并。 在老的部署中,下面的配置是针对 Historicals 和 MiddleManagers 进程的: Historical(独立服务器部署) druid.processing.buffer.sizeBytes=500000000 druid.processing.numMergeBuffers=8 druid.processing.numThreads=31 MiddleManager(独立服务器部署) druid.worker.capacity=8 druid.indexer.fork.property.druid.processing.numMergeBuffers=2 druid.indexer.fork.property.druid.processing.buffer.sizeBytes=100000000 druid.indexer.fork.property.druid.processing.numThreads=1 在集群部署环境中,我们可以选择使用 2 个服务器来运行上面的 2 个服务,这 2 个服务器的配置为 16CPU 和 128GB RAM 。 我们将会按照下面的配置方式进行配置: Historical druid.processing.numThreads: 基于配置的新硬件环境,设置为 (num_cores - 1) druid.processing.numMergeBuffers: 针对独立服务器使用的数量使用分裂因子相除 druid.processing.buffer.sizeBytes: 保持不变 MiddleManager: druid.worker.capacity: 针对独立服务器使用的数量使用分裂因子相除 druid.indexer.fork.property.druid.processing.numMergeBuffers: 保持不变 druid.indexer.fork.property.druid.processing.buffer.sizeBytes: 保持不变 druid.indexer.fork.property.druid.processing.numThreads: 保持不变 在完成上面配置后的结果如下: 集群 Historical (使用 2 个数据服务器) druid.processing.buffer.sizeBytes=500000000 druid.processing.numMergeBuffers=8 druid.processing.numThreads=31 集群 MiddleManager (使用 2 个数据服务器) druid.worker.capacity=4 druid.indexer.fork.property.druid.processing.numMergeBuffers=2 druid.indexer.fork.property.druid.processing.buffer.sizeBytes=100000000 druid.indexer.fork.property.druid.processing.numThreads=1 Query 服务 你可以将已经在独立服务器部署中存在的配置文件拷贝到 conf/druid/cluster/query 目录中完成部署。 如果新的服务器的硬件配置和独立服务器的配置是相对的话,新的部署不需要做修改。 刷新部署 deployment 如果你使用下面的服务器配置环境为示例的话: 1 Master server (m5.2xlarge) 2 Data servers (i3.4xlarge) 1 Query server (m5.2xlarge) 在 conf/druid/cluster 文件夹中的配置文件已经针对上面的硬件环境进行了优化,针对基本情况的使用来说,你不需要针对上面的配置进行修改。 如果你选择使用不同的硬件的话,页面 basic cluster tuning guide 中的内容能够帮助你对你的硬件配置做一些选择。 https://www.ossez.com/t/druid/13649
在实际的生产环境中,我们建议你使用专用的 ZK 集群来进行部署。ZK 的集群与 Druid 的集群部署是分离的。 在 conf/druid/cluster/_common/common.runtime.properties 配置文件中,设置 druid.zk.service.host 为 connection string。 在连接配置中使用的是逗号分隔符(host:port 对),每一个对应的是一个 ZK 的服务器,(例如, “127.0.0.1:4545” or “127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002”)。 你也可以选择在 Master 服务器上运行 ZK,而不使用专用的 ZK 集群。 如果这样做的话,我们建议部署 3 个 Master 服务服务器,以便具有 ZK 仲裁(因为 Zookeeper 的部署至少需要 3 个服务器,并且服务器的总数量为奇数)。 https://www.ossez.com/t/druid-zookeeper/13648

如果你希望从 Hadoop 集群中加载数据,那么你需要对你的 Druid 集群进行下面的一些配置: 更新 conf/druid/cluster/middleManager/runtime.properties 文件中的 druid.indexer.task.hadoopWorkingPath 配置选项。 将 HDFS 配置路径文件更新到一个你期望使用的临时文件存储路径。druid.indexer.task.hadoopWorkingPath=/tmp/druid-indexing 为通常的配置。 将你的 Hadoop XMLs配置文件(core-site.xml, hdfs-site.xml, yarn-site.xml, mapred-site.xml)放到你的 Druid 进程中。 你可以将 conf/druid/cluster/_common/core-site.xml, conf/druid/cluster/_common/hdfs-site.xml 拷贝到 conf/druid/cluster/_common 目录中。 请注意,你不需要为了从 Hadoop 中载入数据而使用 HDFS 深度存储。 例如,如果您的集群在 Amazon Web Services 上运行,即使已经使用 Hadoop 或 Elastic MapReduce 加载数据,我们也建议使用 S3 进行深度存储。 更多信息可以看基于Hadoop的数据摄取部分的文档。 https://www.ossez.com/t/druid-hadoop/13647

配置 metadata 存储和深度存储(deep storage) 从独立服务器部署上合并到集群 如果您已经有一个独立服务器的部署实例,并且希望在整个迁移过程中保留数据,请在对元数据进行迁移之前先阅读: metadata migration deep storage migration 本指南中的元数据迁移是针对你将原数据存储在 Derby 数据库中,同时你的深度存储也是使用的 Derby 数据库。 如果你在单实例部署的服务器上已经使用了非 Derby 的数据库存储元数据或者分布式深度存储的那,那么你可以在新的集群环境中使用已经存在并且使用的存储方案。 本指南还提供了从本地深度存储中进行段合并的信息。 集群环境的部署是需要配置深度存储的,例如 S3 或 HDFS。 如果单实例部署已在使用分布式深度存储,则可以在新集群中继续使用当前的深度存储。 元数据存储 在 conf/druid/cluster/_common/common.runtime.properties 配置文件中,替换 “metadata.storage.*” 的的属性来确定元数据存储的服务器地址。 元数据通常是存储在数据库中的,因此你可以在这里配置你的数据库服务器地址。 druid.metadata.storage.connector.connectURI druid.metadata.storage.connector.host 在实际的生产环境中,我们推荐你使用独立的元数据存储数据库例如 MySQL 或者 PostgreSQL 来增加冗余性。 这个配置将会在 Druid 服务器外部配置一个数据库连接来保留一套元数据的配置信息,以增加数据冗余性。 MySQL extension 和 PostgreSQL extension 页面中有如何对扩展进行配置和对数据库如何进行初始化的说明,请参考上面页面中的内容。 深度存储 Druid 依赖分布式文件系统或者一个大对象(blob)存储来对数据进行存储。 最常用的深度存储的实现通常使用的是 S3 (如果你使用的是 AWS 的话)或者 HDFS(如果你使用的是 Hadoop 部署的话)。 S3 在文件 conf/druid/cluster/_common/common.runtime.properties, 添加 “druid-s3-extensions” 到 druid.extensions.loadList。 在 “Deep Storage” 和 “Indexing service logs” 部分的配置中,注释掉本地存储的配置。 在 “Deep Storage” 和 “Indexing service logs” 部分的配置中,取消注释 “For S3” 部分有关的配置。 在完成上面的操作后,你的配置文件应该看起来和下面的内容相似: druid.extensions.loadList=["druid-s3-extensions"] #druid.storage.type=local #druid.storage.storageDirectory=var/druid/segments druid.storage.type=s3 druid.storage.bucket=your-bucket druid.storage.baseKey=druid/segments druid.s3.accessKey=... druid.s3.secretKey=... #druid.indexer.logs.type=file #druid.indexer.logs.directory=var/druid/indexing-logs druid.indexer.logs.type=s3 druid.indexer.logs.s3Bucket=your-bucket druid.indexer.logs.s3Prefix=druid/indexing-logs 请参考 S3 extension 页面中的内容来获得更多的信息。 HDFS 在文件 conf/druid/cluster/_common/common.runtime.properties, 添加 “druid-hdfs-storage” 到 druid.extensions.loadList。 在 “Deep Storage” 和 “Indexing service logs” 部分的配置中,注释掉本地存储的配置。 在 “Deep Storage” 和 “Indexing service logs” 部分的配置中,取消注释 “For HDFS” 部分有关的配置。 在完成上面的操作后,你的配置文件应该看起来和下面的内容相似: druid.extensions.loadList=["druid-hdfs-storage"] #druid.storage.type=local #druid.storage.storageDirectory=var/druid/segments druid.storage.type=hdfs druid.storage.storageDirectory=/druid/segments #druid.indexer.logs.type=file #druid.indexer.logs.directory=var/druid/indexing-logs druid.indexer.logs.type=hdfs druid.indexer.logs.directory=/druid/indexing-logs 同时, 在你 Druid 启动进程的的 classpath 中,请替换掉你的 Hadoop 配置 XMLs 文件(core-site.xml, hdfs-site.xml, yarn-site.xml, mapred-site.xml),或者你可以直接拷贝上面的文件到 conf/druid/cluster/_common/ 中。 请参考 HDFS extension 页面中的内容来获得更多的信息。 https://www.ossez.com/t/druid/13645

选择操作系统 我们推荐你使用任何你喜欢的 Linux 操作系统。同时你需要安装: Java 8 或者更新的版本 警告: Druid 目前只能官方的支持 Java 8。如果你使用其他的 JDK 版本,那么很多功能可能是实践性的的。 如果需要的话,你可以在你的系统环境中定义环境变量 DRUID_JAVA_HOME 或 JAVA_HOME,来告诉 Druid 到哪里可以找到需要的 JDK 版本。 可以运行 Druid 程序中的 bin/verify-java 脚本来查看当前运行的 Java 版本。 你的操作系统包管理工具应该能够帮助你在操作系统中安装 Java。 如果你使用的是基于 Ubuntu 的操作系统,但是这个操作系统没有提供的最新版本的 Java 的话,请尝试访问 WebUpd8 页面中的内容: packages for those OSes 。 下载发行版本 首先,需要下载并且解压缩相关的归档文件。 最好先在单台计算机上进行相关操作。因为随后你需要在解压缩的包内对配置进行修改,然后将修改后的配置发布到所有的其他服务器上。 apache-druid-0.21.1 下载地址 在控制台中使用下面的命令来进行解压: tar -xzf apache-druid-apache-druid-0.21.1-bin.tar.gz cd apache-druid-apache-druid-0.21.1 在解压后的包中,你应该能够看到: LICENSE 和 NOTICE 文件 bin/* - 启动或停止的脚本,这是针对独立服务器进行部署的,请参考页面: 独立服务器部署快速指南 conf/druid/cluster/* - 针对集群部署的配置和设置文件 extensions/* - Druid 核心扩展 hadoop-dependencies/* - Druid Hadoop 依赖 lib/* - Druid 核心库和依赖 quickstart/* - 独立服务器配置的相关文件,这是针对独立服务器进行部署的,请参考页面: 独立服务器部署快速指南 如果你需要让你的集群能够启动的话,我们将会对 conf/druid/cluster/ 中的内容进行编辑。 从独立服务器部署上进行合并 如果需要完成后续页面的部署和配置的话,你需要对 conf/druid/cluster/ 中的内容进行编辑。 如果你已经有一个正在运行的独立服务器部署的话,请拷贝你已经存在的配置文件到 conf/druid/cluster 文件夹中,以保证你已有的配置文件不丢失。 https://www.ossez.com/t/druid/13644