如果你已经有一个已经存在并且独立运行的独立服务器部署的话,例如在页面 single-server deployment examples 中部署的服务器, 现在你希望将这个独立部署的服务器合并到集群的部署方式中的话,下面的这部分内容将会帮助你完成这个切换和合并的过程。 这个过程包括有如何对硬件进行的选择和针对 Master/Data/Query 服务器应该如何进行组织。 主服务器(Master Server) 针对主服务器主要需要考虑的就是 Coordinator 和 Overlord 进程的 CPU 使用和 RAM 内存的 heaps。 从单独服务器部署的实例中找到 Coordinator 和 Overlord 进程的总计 heap 内存使用大小,然后在新的集群服务上选择硬件时候的 RAM 内存选择,需要有这 2 个进程合并 heap 的大小。 同时还需要准备为这台服务器留够足够的内存供其他进程使用。 针对服务器使用的 CPU 内核,你可以只选择在单独部署情况下的 1/4 即可。 数据服务器(Data server) 当对数据服务器进行选择的时候,主要考虑的是 CPU 数量和 RAM 内存数量,同时如果能够使用 SSD 固态硬盘就更好了。 在针对集群的部署中,如果能够使用多台服务器来部署数据服务器就更好了,因为这样能够让集群拥有更多的冗余来保障持续运行。 当针对数据服务器选择硬件的时候,你可以选择分裂因子 ‘N’,针对原始独立服务器部署的时候的 CPU/RAM 的数量除以 N, 然后按照除以 ‘N’ 后的结果来确定集群服务器的硬件要求。 针对 Historical/MiddleManager 的配置调整和分离将会在本页面后部分的指南中进行说明。 查询服务器(Query server) 当对数据服务器进行选择的时候,主要考虑的是 CPU 数量,RAM 内存数量和 Broker 进程的的 heap 内存加上直接内存(direct memory),以及 Router 进程的 heap 内存。 将 Broker 和 Router 进程在独立服务器上使用的内存数量相加,然后选择的查询服务器的内存需要足够大的内存来覆盖 Broker/Router 进程使用内存相加的结果。 同时还需要准备为这台服务器留够足够的内存供其他进程使用。 针对服务器使用的 CPU 内核,你可以只选择在单独部署情况下的 1/4 即可。 请参考 basic cluster tuning guide 页面中的内容,来确定如何计算 Broker/Router 进程使用的内存。 https://www.ossez.com/t/druid/13643
Apache Druid 被设计部署为可扩展和容错的集群部署方式。 在本文档中,我们将会设置一个示例集群,并且进行一些讨论,你可以进行那些修改来满足你的需求。 这个简单的集群包括有下面的特性: 主服务器(Master Server)将会运行 Coordinator 和 Overlord 进程 2 个可扩展和容错的数据服务器将会运行 Historical 和 MiddleManager 进程 一个查询服务器(Query Server)将会运行 Broker 和 Router 进程 在生产环境中,我们建议你部署多个 Master 服务器和多个 Query 服务器,服务器的高可用性(fault-tolerant)配置与你的数据特性和容错性要求息息相关。 但是你可以使用一个主服务器(Master Server) 和 一个查询服务器(Query Server)来启动服务,随着需求的增加你可以随时增加更多的服务器节点。 选择硬件 全新部署 如果你没有已经存在的 Druid 集群,但是你希望开始在你的环境中使用集群方式部署 Druid,本文档将会使用预配置(pre-made configurations)内容来帮助你开始部署 Druid 的集群。 主服务器(Master Server) Coordinator 和 Overlord 进程将会负责处理 metadata 数据和在你集群中进行协调。这 2 个进程可以合并在同一个服务器上。 在本示例中,我们将会在 AWS m5.2xlarge 部署一个评估的服务器和实例。 AWS 上面硬件的配置为: 8 vCPUs 31 GB RAM 有关本服务器的配置信息和有关硬件大小的建议,可以在文件 conf/druid/cluster/master 中找到。 数据服务器(Data server) Historicals 和 MiddleManagers 可以合并到同一个服务器上,这个 2 个进程在你的集群中用于处理实际的数据。通常来说越大 CPU, RAM, SSDs硬盘越好。 在本示例中,我们将会在 i3.4xlarge 部署一个评估的服务器和实例。 AWS 上面硬件的配置为: 16 vCPUs 122 GB RAM 2 * 1.9TB SSD storage 有关本服务器的配置信息和有关硬件大小的建议,可以在文件 conf/druid/cluster/data 中找到。 查询服务器(Query server) Druid Brokers 可以接受查询,并且将接受的查询发送到集群中处理。同时他们也负责维护内存中的查询缓存, 常来说越大的 CPU, RAM 越好。 在本示例中,我们将会在 m5.2xlarge 部署一个评估的服务器和实例。 AWS 上面硬件的配置为: 8 vCPUs 31 GB RAM 你也可以考虑在运行 Broker 进程的查询服务器上部署任何开源的 UI 或者查询库。 有关本服务器的配置信息和有关硬件大小的建议,可以在文件,可以在文件 conf/druid/cluster/query 中找到。 其他硬件大小 上面的示例集群配置是从多种确定 Druid 集群可能的配置方式中选择的一个示例。 您可以根据自己的特定需求和要求来选择 较小/较大的硬件配置或 较少/更多的服务器数量。 如果你的使用实例有比较复杂的可扩展性要求,你也可以选择不将进程合并到服务器上的配置方案,而针对每一个进程配置一台服务器(例如,你可以配置一个独立的 Historical 服务器)。 有关更多的配置信息,请参考页面 basic cluster tuning guide 中的内容,能够帮助你如何对你的配置进行配置和扩展。 https://www.ossez.com/t/druid/13642

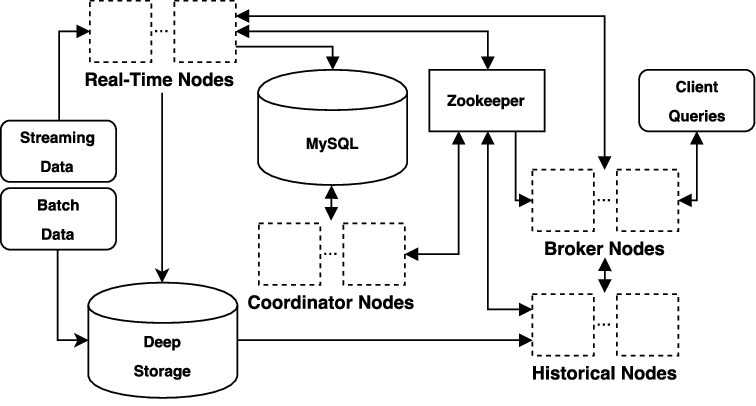
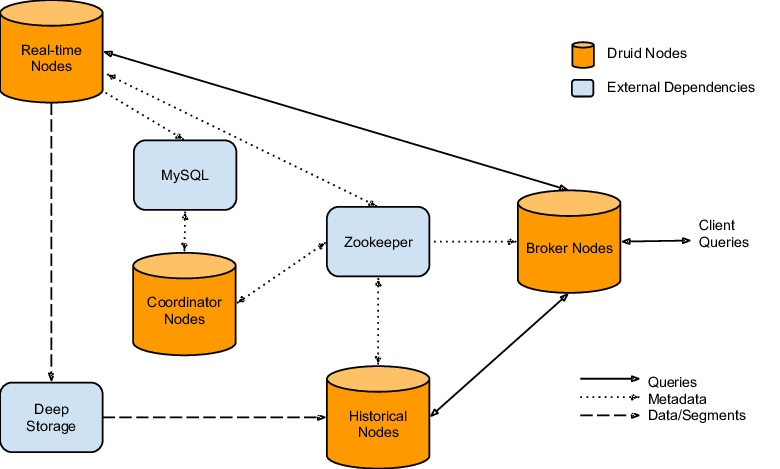
根据官方的文档,我们整理出了下面的这张进程的图。 在集群的部署环境下,你可以按照每个服务器来部署,换句话说就是有 3 台服务器,但是每台服务器上有 2 个进程。 你也可以每个进程部署一台服务器,那么这里将会需要有 6 台服务器。 主服务器(Master Server) 简单来说,主服务器的功能主要是对元数据进行维护和在不同进程之间进行数据的协调。 在这个服务器上,通常定义有下面 2 个进程: Coordinator 和 Overlord 进程。 这 2 个进程可以合并在同一个服务器上,将会负责处理 metadata 数据和在你集群中进行协调。 数据服务器(Data server) 从字面上来看就是对数据进行处理的。 在这个服务器上定义有 2 个进程: Historicals 和 MiddleManagers 进程 Historicals 通常被考虑用来处理历史数据,MiddleManagers 通常被考虑在当前的数据情况,段情况和对数据进行导入。 这 2 个进程可以合并在同一个服务器上,这个 2 个进程在你的集群中用于处理实际的数据。通常来说越大 CPU, RAM, SSDs硬盘越好。 查询服务器(Query server) 按照字母的理解来说,查询服务器就是为查询服务的,通常会从界面或者 HTTP 或者命令行中获得需要查询的脚本,然后将脚本处理成可用 JSON 格式,或者在处理的时候有错误需要返回给请求的发送者。 为了加快查询的效果,我们可能会对查询以及查询的结果缓存到内存中,因此 Druid Brokers 可以接受查询,并且将接受的查询发送到集群中处理。 同时他们也负责维护内存中的查询缓存, 常来说越大的 CPU, RAM 越好。 Router 这个进程如果从字面来看会有点困惑,你可能会认为是为了对查询进行调度使用的,其实 Router 就是在 Druid 提供 UI 界面的。 可以理解为 Router 是应因为服务,在这里 Router 启动后可以对 Druid 当前的情况进行查询,同时也可以进行查询,使用的是 NodeJs 部署的。 正是因为这样,Druid 的编译就只能在 Linux 下面完成,可以尝试在 Windows 环境下进行编译,但是你可能会遇到 NodeJS 的错误。 要跳过这个错误,就不编译 UI 界面就行。 https://www.ossez.com/t/docker/13640
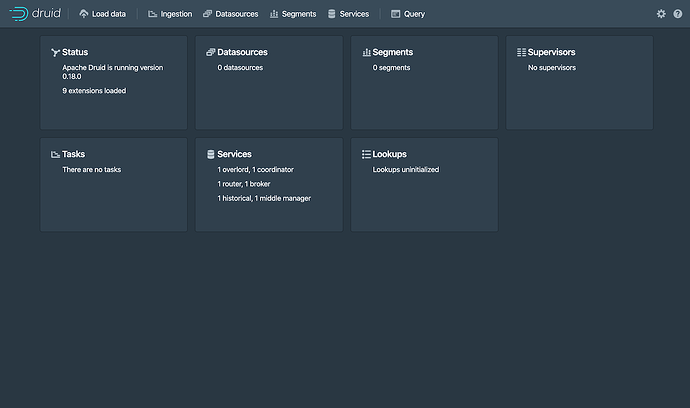
Docker 在本 Docker 的快速指南中,我们将从 Docker Hub 下载 Apache Druid 镜像,在一台机器上安装并使用 Docker 和 Docker Compose 。 在完成初始设置后,集群将准备好加载数据。 同时,如果你已经完成了下面内容的阅读的话将会更好的帮助你理解 Docker 安装配置的相关内容。 Druid 基本概述 数据导入概述 如果你还能对 Docker 使用的相关知识有所了解的,也能够更好的帮助你在 Docker 上使用 Druid。 安装前提 Docker 开始安装 Druid 的源代码中包含一个用于示例的 docker-compose.yml 文件。 这个文件可以从 Docker Hub中获取一个镜像,并可以使用这个镜像进行 Docker 的 Druid 配置和部署。 Compose 文件 docker-compose.yml 示例文件将会为每一个 Druid 服务创建一个容器,包括 Zookeeper 和作为元数据存储 PostgreSQL 容器。 同时还会创建一个 druid_shared 的卷,并且这个卷将会在容器的挂载点为 opt/shared。这个挂载点将会被用在深度存储来保证在段和任务日志之间进行共享。 Druid 容器是通过 environment file 进行配置的。 配置 Druid Docker 容器的配置是通过环境变量完成的。环境变量的路径指定请参考文档:标准 Druid 配置文件 中的内容。 特殊的环境变量: JAVA_OPTS – 设置 java options DRUID_LOG4J – 设置完成的 log4j.xml DRUID_LOG_LEVEL – 覆盖在 log4j 中的默认日志级别 DRUID_XMX – 设置 Java Xmx DRUID_XMS – 设置 Java Xms DRUID_MAXNEWSIZE – 设置 Java 最大 new 的大小 DRUID_NEWSIZE – 设置 Java new 的大小 DRUID_MAXDIRECTMEMORYSIZE – 设置 Java 最大直接内存大小 DRUID_CONFIG_COMMON – druid “common” 属性文件的完整路径 DRUID_CONFIG_${service} – druid “service” 属性文件的完整路径 除了上面的特殊的环境变量外,在容器启动的时候 Druid 的脚本还将尝试使用以 druid_ 为前缀的环境变量来对变量进行配置。 例如,针对 Druid 在容器中的进程使用的环境变量: druid_metadata_storage_type=postgresql 将被转换为 Druid 的 docker-compose.yml 文件,展示了如何使用一个环境配置文件来完成所有 Druid 的配置。 但是,在生产环境中,建议使用 DRUID_COMMON_CONFIG 和DRUID_CONFIG_${service} 来为服务相关的环境指派专门的配置参数。 启动集群 docker-compose up 命令来在 shell 中直接启动集群。 如果你希望在后台环境中启动集群,请运行 docker-compose up -d 命令。 如果你使用的是示例文件目录,那么你需要从 distribution/docker/ 目录来启动 Docker 的集群。 当你的集群完成所有的启动后,你可以通过浏览器访问 http://localhost:8888 控制台页面。 Druid router 进程 提供了 Druid 控制台(Druid console) 显示的界面。 所有的 Druid 进程完全启动需要几秒钟的时间。如果在 Druid 进程启动的时候,立即打开控制台的话,你可能会看到一些可安全错误,这些安全错误是可以忽略的,直接刷新页面即可。 至此,你可以继续 快速使用(Quickstart) 页面第 4 步导入数据的内容。 如果你还希望加载一些其他的依赖的话,你可以直接对 docker-compose.yml 文件进行编辑后重启 Docker。 Docker 内存的需求 如果你在 Docker 启动的时候发现存在进程崩溃,并且错误代码为 137 的话,表明你的 Docker 的内存不够。 在测试阶段,你可以为你的 Docker 指派 6G 左右的内存。 上图显示了 Docker Hub 中的 Druid 项目。 因 Druid 更多的时候需要使用集群的方式,因此 Docker 的配置可以更快的让用户完成配置后并开始使用。 https://www.ossez.com/t/docker-druid/13639#docker-1
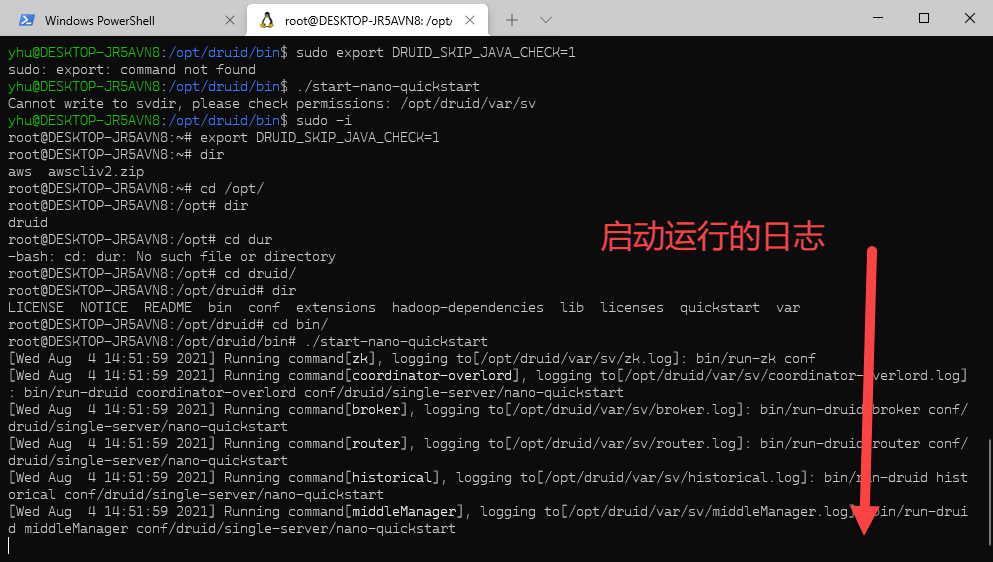
Druid 包含有一组可用的参考配置和用于单机部署的启动脚本: nano-quickstart micro-quickstart small medium large xlarge micro-quickstart 适合于笔记本电脑等小型计算机,主要用于能够快速评估 Druid 的使用场景。 其他的配置包含有针对使用独立服务器进行部署的配置,这些配置通常需要与 AWS 的 i3 系列 EC2 服务器等同才行。 这些示例配置的启动脚本与 Druid 服务一起运行单个 ZooKeeper 实例来运行,你也也可以选择单独部署 ZooKeeper。 在示例程序中的 Druid Coordinator 和 Overlord 作为一个独立的进程同时运行,使用的可选配置为 druid.coordinator.asOverlord.enabled=true, 相关的内容请参考 Coordinator configuration documentation 页面中的内容。 我们虽然为大型单台计算机提供了配置的实例,但是在更加真实和大数据的环境下,我们建议在集群方式下部署 Druid,请参考 clustered deployment 页面中的内容。 通过集群方式的部署,能够更好的增加的 Druid 容错能力和扩展能力。 Nano-Quickstart: 1 CPU, 4GiB RAM 启动命令: bin/start-nano-quickstart 配置目录: conf/druid/single-server/nano-quickstart Micro-Quickstart: 4 CPU, 16GiB RAM 启动命令: bin/start-micro-quickstart 配置目录: conf/druid/single-server/micro-quickstart Small: 8 CPU, 64GiB RAM (~i3.2xlarge) 启动命令: bin/start-small 配置目录: conf/druid/single-server/small Medium: 16 CPU, 128GiB RAM (~i3.4xlarge) 启动命令: bin/start-medium 配置目录: conf/druid/single-server/medium Large: 32 CPU, 256GiB RAM (~i3.8xlarge) 启动命令: bin/start-large 配置目录: conf/druid/single-server/large X-Large: 64 CPU, 512GiB RAM (~i3.16xlarge) 启动命令: bin/start-xlarge 配置目录: conf/druid/single-server/xlarge 启动运行的日志: 通过控制台访问的端口为 8888,范围的地址链接为:http://localhost:8888 正常的话,你应该能够看到下面的控制台界面: 上面的界面表示你本地的测试环境已经配置成功了。 https://www.ossez.com/t/druid/13638
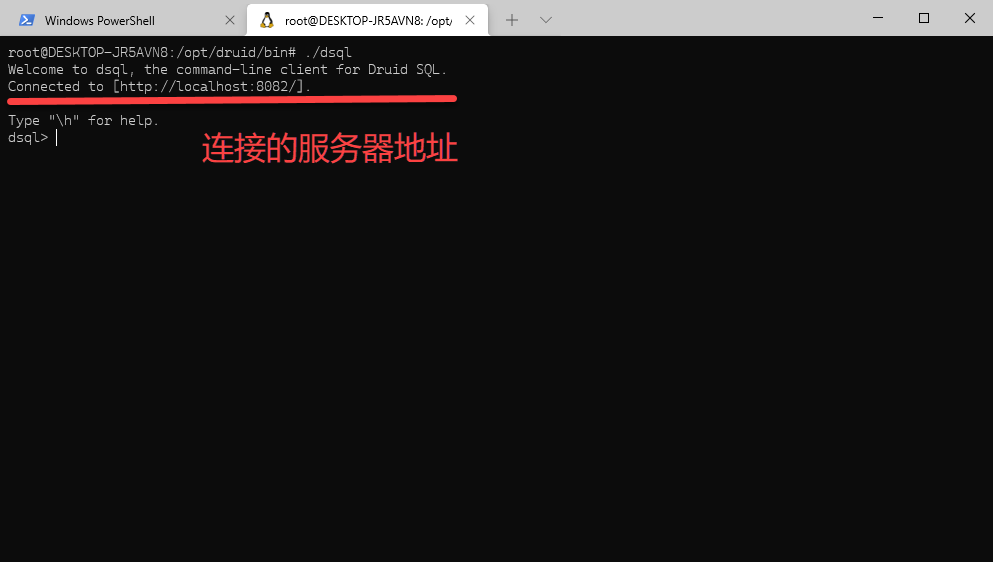
如果直接使用 ./dsql 运行命令行工具的话,将会显示连接的服务器地址为 http://localhost:8082/ 如果需要连接到其他的服务器地址,应该如何进行操作。 问题和解决 如果你希望连接到其他的服务器地址的话,你需要使用连接参数 -H 请注意,这里的 H 是大写 H 那么命令的执行为: ./dsql -H http://10.0.0.1:8080/ 来进行服务器的连接。 https://www.ossez.com/t/druid-dsql/13636
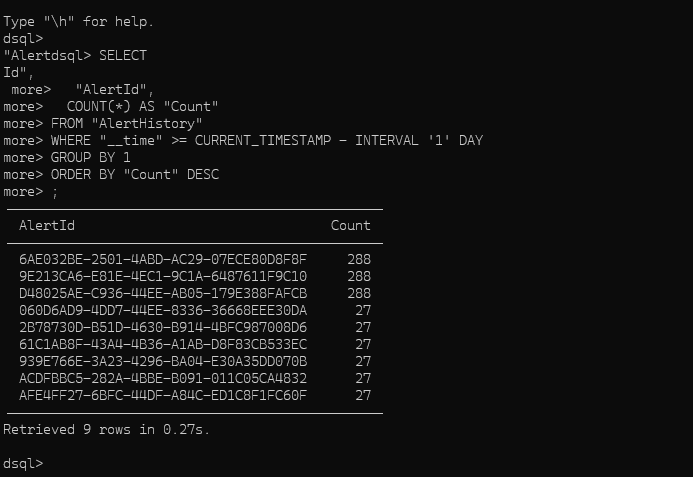
为了便于使用,Druid 包中还提供了一个 SQL 命令行客户端工具,这个工具位于 bin/dsql 目录中。 如果你直接运行 bin/dsql 的话,你将会看到下面的提示输出: Welcome to dsql, the command-line client for Druid SQL. Type "\h" for help. dsql> 如果希望进行查询的话,将你的 SQL 张贴到 dsql 提示光标后面,然后单击回车: dsql> SELECT page, COUNT(*) AS Edits FROM wikipedia WHERE "__time" BETWEEN TIMESTAMP '2015-09-12 00:00:00' AND TIMESTAMP '2015-09-13 00:00:00' GROUP BY page ORDER BY Edits DESC LIMIT 10; ┌──────────────────────────────────────────────────────────┬───────┐ │ page │ Edits │ ├──────────────────────────────────────────────────────────┼───────┤ │ Wikipedia:Vandalismusmeldung │ 33 │ │ User:Cyde/List of candidates for speedy deletion/Subpage │ 28 │ │ Jeremy Corbyn │ 27 │ │ Wikipedia:Administrators' noticeboard/Incidents │ 21 │ │ Flavia Pennetta │ 20 │ │ Total Drama Presents: The Ridonculous Race │ 18 │ │ User talk:Dudeperson176123 │ 18 │ │ Wikipédia:Le Bistro/12 septembre 2015 │ 18 │ │ Wikipedia:In the news/Candidates │ 17 │ │ Wikipedia:Requests for page protection │ 17 │ └──────────────────────────────────────────────────────────┴───────┘ Retrieved 10 rows in 0.06s. 如下图,就是我们使用 dsql 工具连接上我们一个服务器后进行查询的返回界面 上面的数据为服务器上真实的数据。 https://www.ossez.com/t/druid-dsql/13634
提示的错误信息如下: Import error: No module name urllib2 问题和解答 出现这个问题的原因可能是你的 Python 版本不正确或者没有安装 Python。 运行命令 apt-get install python 来安装 Python,然后再次运行 ./dsql 你应该能够看到命令行提示工具。 如果能看到这个提示符的话,就表示 dsql 的配置已经正确了。 https://www.ossez.com/t/druid-dsql-urllib2/13635
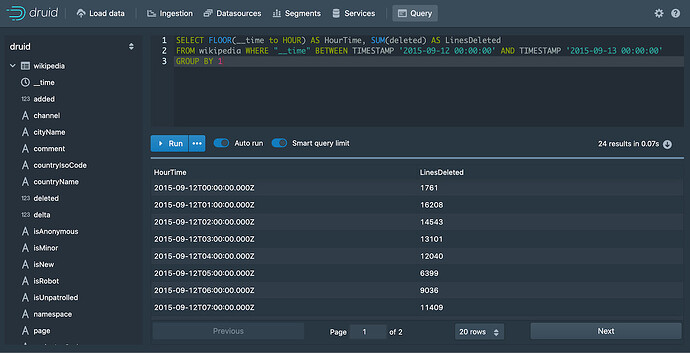
下面是你可以在 Druid 上尝试进行查询的一些实例供你测试: 对时间进行查询 SELECT FLOOR(__time to HOUR) AS HourTime, SUM(deleted) AS LinesDeleted FROM wikipedia WHERE "__time" BETWEEN TIMESTAMP '2015-09-12 00:00:00' AND TIMESTAMP '2015-09-13 00:00:00' GROUP BY 1 基本的 group by SELECT channel, page, SUM(added) FROM wikipedia WHERE "__time" BETWEEN TIMESTAMP '2015-09-12 00:00:00' AND TIMESTAMP '2015-09-13 00:00:00' GROUP BY channel, page ORDER BY SUM(added) DESC Druid 能够进行一些比较灵活的查询,因此对基本的 SQL 掌握还是需要的。 https://www.ossez.com/t/druid/13633
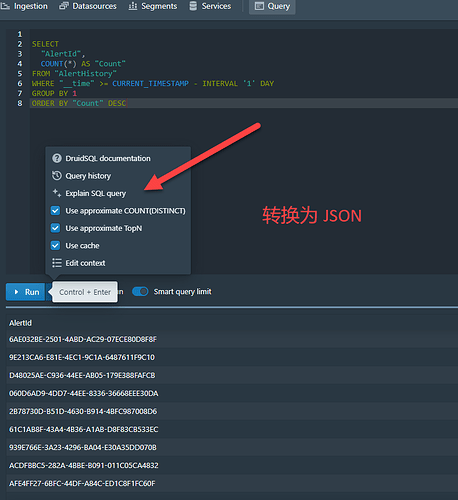
Druid 控制台中提供了一个将 SQL 脚本转换为 JSON 格式的方法。 JSON 格式便于通过 HTTP 发送给后台处理,因此有些 SQL 我们希望转换为 JSON 格式。 选择菜单 可以按照下面的菜单中的选择项进行选择,然后单击运行 根据官方的文档说明,Druid 的所有查询都是使用 JSON 格式进行查询的。 哪怕你使用的是 SQL ,Druid 还是会将你的 SQL 转换为 JSON 后查询。 可以从上面的语句中看到,Select 对应 JSON 中的查询类型为 topN。 因为在 Druid 的 JSON 查询中,提供了更多的功能和配置参数,因此官方还是建议对 JSON 查询有所了解。 https://www.ossez.com/t/druid-druid-console-sql-json/13632