随着 GitHub 系统的更新,在 2021 年的 8月底将不再支持使用用户名和密码的方式访问仓库了。 用户需要使用用户名和访问 Token 的方式来访问。 这篇文章就是指导你如何创建访问的秘钥。 进入 GitHub 设置 在登录成功 GitHub 后,选择系统设置。 进入开发设置 在进入的设置页面中,选择左侧的开发设置。 选择访问 Token 在随后的页面中,选择个人的访问 Token。 到这里就是如何设置 Token 的访问路径。 设置名称和权限 根据不同的 Token 会有不同的访问权限。 你可以对房屋的权限进行设置和修改。 在这个界面中,设置用户名后就可以设置权限了。 至此,访问的 Token 就已经设置完成了,在使用 Git 需要登录的时候,你需要使用用户名和这个 Token 同时进行登录。 需要注意的是,这个 Token 需要保存,以避免丢失。 https://www.ossez.com/t/github-access-token/13615
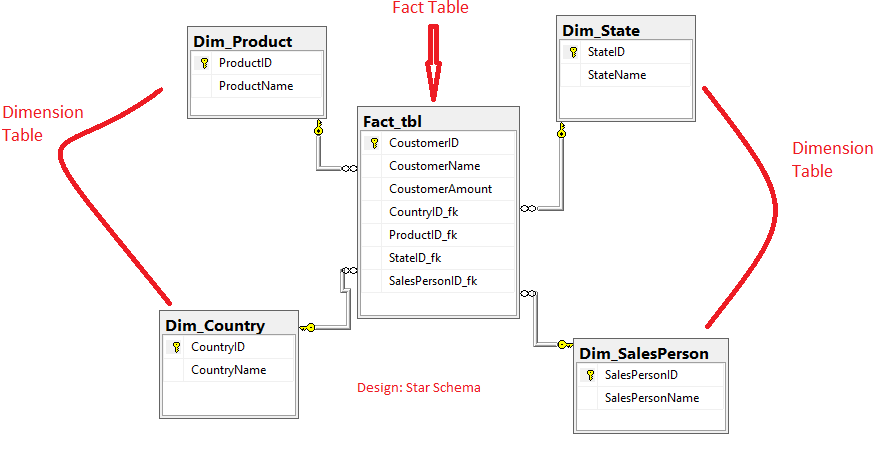
与 Fact Table 对应的表是 Dimension Table。 这 2 个表是数据仓库的两个概念,为数据仓库的两种类型表。 从保存数据的角度来说,本质上没区别,都是表。 区别主要在数据和用途上,Fact Table 用来存 fact 数据,就是一些可以计量的数据和可加性数据,数据数量,金额等。 Dimension Table 用来存描述性的数据,比如说用来描述 Fact 表中的数据,如区域,销售代表,产品等。 https://www.ossez.com/t/fact-table/13611
在 SQL 中,基数(cardinality)的定义为一个数据列中独一无二数据的数量。 高基数(High-Cardinality)的定义为在一个数据列中的数据基本上不重复,或者说重复率非常低。 例如我们常见的识别号,邮件地址,用户名等都可以被认为是高基数数据。 例如我们常定义的 USERS 数据表中的 USER_ID 字段,这个字段中的数据通常被定义为 1 到 n。 每一次一个新的用户被作为记录插入到 USERS 表中,一个新的记录将会被创建, 字段 USER_ID 将会使用一个新的数据来标识这个被插入的数据。 因为 USER_ID 中插入的数据是独一无二的,因此这个字段的数据技术就可以被考虑认为是 高基数(High-Cardinality) 数据。 https://www.ossez.com/t/topic/13610
Edge 浏览器提供了一个小亮点功能,就是不需要使用其他的插件来生成 URL 的 QR 代码。 这个功能能够让你比较容易的将当前的网页通过发送给手机客户端。 这个功能是隐藏在 URL 中的。 在当前访问的网页中的 URL,单击地址栏的后部分。 随后将会显示URL 被选择了,然后单击生成 QR 的按钮。 随后的界面,将会显示出当前页面的 QR 代码。 这个时候你就可以用手机的 QR 识别或者扫描功能来查看并且分享了。 https://www.ossez.com/t/edge-url-qr/13609
可能是因为没有输出就是正常的。 因为并不是是否确定这个地方是否应该有输出。 在尝试使用命令 ./verify-java 对 Java 的运行环境进行校验的时候,并没有任何输出。 也搜索了下官方的文档,也没有这方面的说明,应该是没有输出就说明没有问题,如果有输出的话就说明需要修改的东西在那里。 https://www.ossez.com/t/apache-druid-java/13606
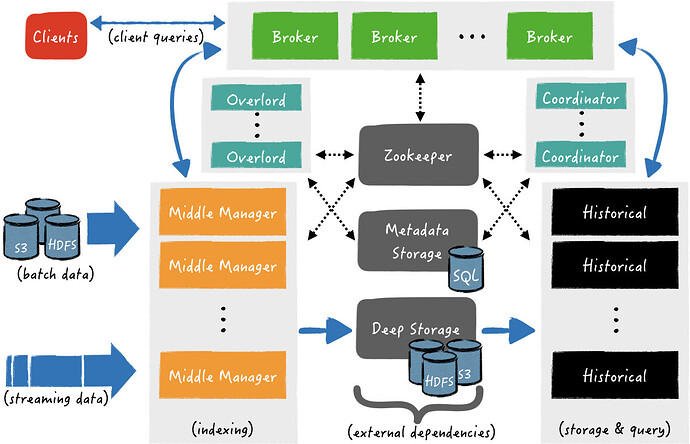
许多公司都已经将 Druid 应用于多种不同的应用场景。请访问 使用 Apache Druid 的公司 页面来了解都有哪些公司使用了 Druid。 如果您的使用场景符合下面的一些特性,那么Druid 将会是一个非常不错的选择: 数据的插入频率非常高,但是更新频率非常低。 大部分的查询为聚合查询(aggregation)和报表查询(reporting queries),例如我们常使用的 “group by” 查询。同时还有一些检索和扫描查询。 查询的延迟被限制在 100ms 到 几秒钟之间。 你的数据具有时间组件(属性)。针对时间相关的属性,Druid 进行特殊的设计和优化。 你可能具有多个数据表,但是查询通常只针对一个大型的分布数据表,但是,查询又可能需要查询多个较小的 lookup 表。 如果你的数据中具有高基数(high cardinality)数据字段,例如 URLs、用户 IDs,但是你需要对这些字段进行快速计数和排序。 你需要从 Kafka,HDFS,文本文件,或者对象存储(例如,AWS S3)中载入数据。 如果你的使用场景是下面的一些情况的话,Druid 不是一个较好的选择: 针对一个已经存在的记录,使用主键(primary key)进行低延迟的更新操作。Druid 支持流式插入(streaming inserts)数据,但是并不很好的支持流式更新(streaming updates)数据。 Druid 的更新操作是通过后台批处理完成的。 你的系统类似的是一个离线的报表系统,查询的延迟不是系统设计的重要考虑。 使用场景中需要对表(Fact Table)进行连接查询,并且针对这个查询你可以介绍比较高的延迟来等待查询的完成。 https://www.ossez.com/t/apache-druid/13604
Apache Druid 是一个实时分析型数据库,旨在对大型数据集进行快速查询和分析(“OLAP” 查询)。 Druid 最常被当做数据库,用以支持实时摄取、高查询性能和高稳定运行的应用场景。 例如,Druid 通常被用来作为图形分析工具的数据源来提供数据,或当有需要高聚和高并发的后端 API。 同时 Druid 也非常适合针对面向事件类型的数据。 通常可以使用 Druid 作为数据源的系统包括有: 点击流量分析(Web 或者移动分析) 网络监测分析(网络性能监控) 服务器存储指标 供应链分析(生产数据指标) 应用性能指标 数字广告分析 商业整合 / OLAP Druid 的核心架构集合了数据仓库(data warehouses),时序数据库(timeseries databases),日志分析系统(logsearch systems)的概念。 如果你对上面的各种数据类型,数据库不是非常了解的话,那么我们建议你进行一些搜索来了解相关的一些定义和提供的功能。 Druid 的一些关键特性包括有: 列示存储格式(Columnar storage format) Druid 使用列式存储,这意味着在一个特定的数据查询中它只需要查询特定的列。 这样的设计极大的提高了部分列查询场景性能。另外,每一列数据都针对特定数据类型做了优化存储,从而能够支持快速扫描和聚合。 可扩展的分布式系统(Scalable distributed system) Druid通常部署在数十到数百台服务器的集群中, 并且可以提供每秒数百万级的数据导入,并且保存有万亿级的数据,同时提供 100ms 到 几秒钟之间的查询延迟。 高性能并发处理(Massively parallel processing) Druid 可以在整个集群中并行处理查询。 实时或者批量数据处理(Realtime or batch ingestion) Druid 可以实时(已经被导入和摄取的数据可立即用于查询)导入摄取数据库或批量导入摄取数据。 自我修复、自我平衡、易于操作(Self-healing, self-balancing, easy to operate) 为集群运维操作人员,要伸缩集群只需添加或删除服务,集群就会在后台自动重新平衡自身,而不会造成任何停机。 如果任何一台 Druid 服务器发生故障,系统将自动绕过损坏的节点而保持无间断运行。 Druid 被设计为 7*24 运行,无需设计任何原因的计划内停机(例如需要更改配置或者进行软件更新)。 原生结合云的容错架构,不丢失数据(Cloud-native, fault-tolerant architecture that won’t lose data) 一旦 Druid 获得了数据,那么获得的数据将会安全的保存在 深度存储 (通常是云存储,HDFS 或共享文件系统)中。 即使单个个 Druid 服务发生故障,你的数据也可以从深度存储中进行恢复。对于仅影响少数 Druid 服务的有限故障,保存的副本可确保在系统恢复期间仍然可以进行查询。 针对快速过滤的索引(Indexes for quick filtering) Druid 使用 Roaring 或 CONCISE 来压缩 bitmap indexes 后来创建索引,以支持快速过滤和跨多列搜索。 基于时间的分区(Time-based partitioning) Druid 首先按时间对数据进行分区,同时也可以根据其他字段进行分区。 这意味着基于时间的查询将仅访问与查询时间范围匹配的分区,这将大大提高基于时间的数据处理性能。 近似算法(Approximate algorithms) Druid应用了近似 count-distinct,近似排序以及近似直方图和分位数计算的算法。 这些算法占用有限的内存使用量,通常比精确计算要快得多。对于精度要求比速度更重要的场景,Druid 还提供了exact count-distinct 和 exact ranking。 在数据摄取的时候自动进行汇总(Automatic summarization at ingest time) Druid 支持在数据摄取阶段可选地进行数据汇总,这种汇总会部分预先聚合您的数据,并可以节省大量成本并提高性能。 https://www.ossez.com/t/druid/13603
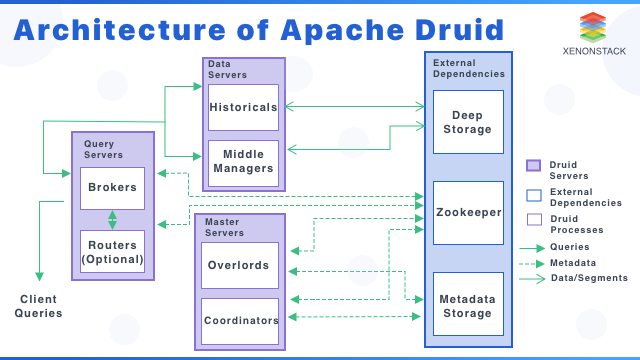
Apache Druid 是一个高性能的实时分析型数据库。 Druid 的主要价值是能够减少检查和查找的时间。 Druid 的工作流被设计为能够快速进行查询并且能够对实时的情况进行分析。 Druid 具有非常强大的 UI 界面,能够让用户进行 即席查询(Ad-Hoc Query),或者能够处理高并发。 针对数据库仓库或一系列的用户使用案例,可以将 Druid 考虑为这些使用场景的开源解决方案。 Ad-Hoc Query 如果你对 Ad-Hoc Query (即席查询)的概念和使用不是是否清楚的话,请自行搜索相关的技术文档。 简单来说:即席查询(Ad Hoc)是用户根据自己的需求,灵活的选择查询条件,系统能够根据用户的选择生成相应的统计报表。 即席查询与普通应用查询最大的不同是普通的应用查询是定制开发的,而即席查询是由用户自定义查询条件的。 即席查询是指那些用户在使用系统时,根据自己当时的需求定义的查询。 对即席查询来说,用户需要查询的内容在开始的时候是不知道的,因此查询需要更多的维度,查询很多时候都是在运行的时候再构建的。 Druid 的查询能够很好的支持即席查询,但同时也带来一些复杂性和学习曲线。 云原生、流原生的分析型数据库 Druid专为需要快速数据查询与摄入的工作流程而设计,在即时数据可见性、即席查询、运营分析以及高并发等方面表现非常出色。 在实际中的众多场景下数据仓库解决方案,都可以考虑将 Druid 作为一种开源的替代解决方案。 请访问 Druid 资源快速导航 页面来简要查看我们收集的相关技术文档和使用案例。 轻松与现有的数据源 Druid 原生支持从 Kafka ,Amazon Kinesis 等消息总线中流式的消费数据, 也同时支持从 HDFS , Amazon S3 等存储服务中批量加载数据。 较传统方案提升近百倍的效率 Druid 创新地在架构设计上吸收和结合了数据仓库, 时序数据库 以及 检索系统 的优势。 在已完成的 基准测试 中针对传统数据输入和查询的解决方案展现强大的性能。 解锁了一种新型的工作流程 Druid 为点击流、APM、供应链、网络监测、市场营销以及其他事件驱动类型的数据分析解锁了一种新型的查询与工作流程, 它专为实时和历史数据高效快速的即席查询而设计。 强大部署能力 Druid 可部署在 AWS/GCP/Azure, 混合云, Kubernetes, 以及裸机上,针对中文环境阿里的云计算平台也提供了无缝集成。 无论在云上还是本地,Druid 都可以轻松部署在基于 *NIX 环境的任何商用硬件上。部署 Druid 是非常简单的,包括集群的扩容或者下线都也同样很简单。 https://www.ossez.com/t/apache-druid/13602
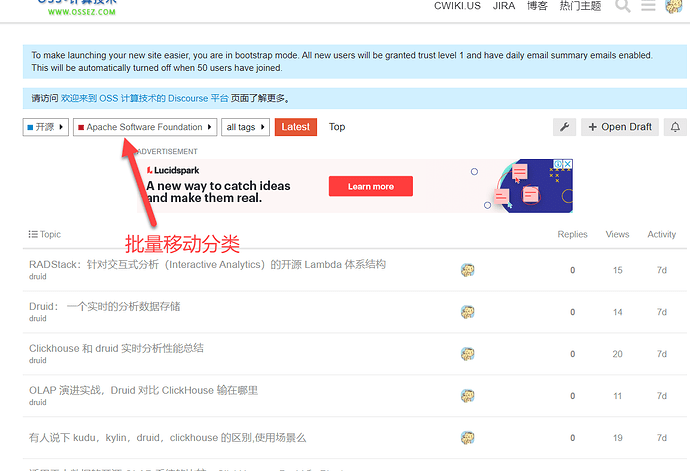
在社区运行一段时间以后,我们可能需要对社区的内容进行调整。 这篇文章介绍了如何在 Discourse 中批量从一个分类移动到另一个分类。 例如,我们需要将下面的主题批量从当前的分类中移动到另外一个叫做 数据库 的分类中。 操作步骤 下面描述了相关的步骤。 选择 选择你需要移动的主题。 这个是操作的第一步,如下图所示,选择主题前面的图标。 然后所有的主题都变成可以选择的选项了,然后再在页面的右侧单击调整的按钮。 批量操作 当你选择批量操作以后,当前的浏览器界面就会弹出一个小对话框。 在这个小对话框中,你可以选择设置分类。 选择设置分类 在随后的界面中,选择设置的分类。 然后保存就可以了。 经过上面的步骤就可以完成对主题的分类的批量移动了。 需要注意的是,主题分类的批量移动不会修改当前主题的的排序,如果你使用编辑方式在主题内调整分类的话,那么调整的主题分类将会排序到第一位。 这是因为在主题内对分类的调整方式等于修改了主题,Discourse 对主题的修改是会更新主题修改日期的,在 Discourse 首页中对页面的排序是按照主题修改后的时间进行排序的,因此会将修改后的主题排序在最前面。 https://www.ossez.com/t/discourse/13601
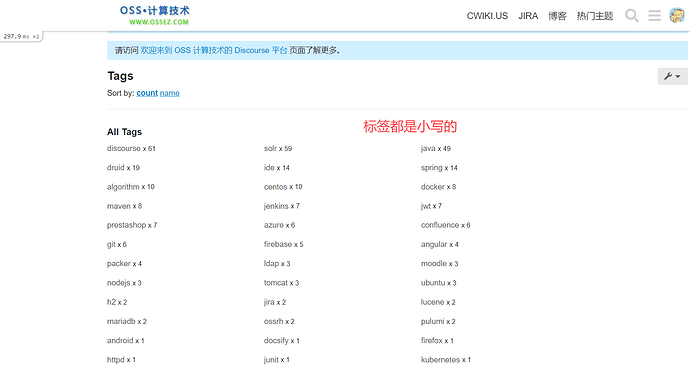
在 Discourse 中使用标签的时候,发现 Discourse 创建的标签都是小写的。 有没有办法让 Discourse 创建的标签可以是大写呢? 深入和解答 Discourse 是允许使用大写的标签的,可以在后台的控制台中进行配置。 可以通过取消上面的选择项来允许标签使用大写。 但是,不建议取消这个的选择。例如标签中的 home = Home = hOme = homE 字符,如果允许大写的话,上面的标签是不相同的,但是实际上,上面的标签是相同的。 基于上面的考虑,所以标签被设置为只使用小写。 例如 GitHub 等很多大的平台都只能使用小写标签。 https://www.ossez.com/t/discourse-tag/13600