
发了点小文,不知不觉过了知乎的百万。 很多时候在于你是不是坚持了,能帮助有需要的人,其实还是蛮开心的。 https://www.usrealestate.io/t/topic/100
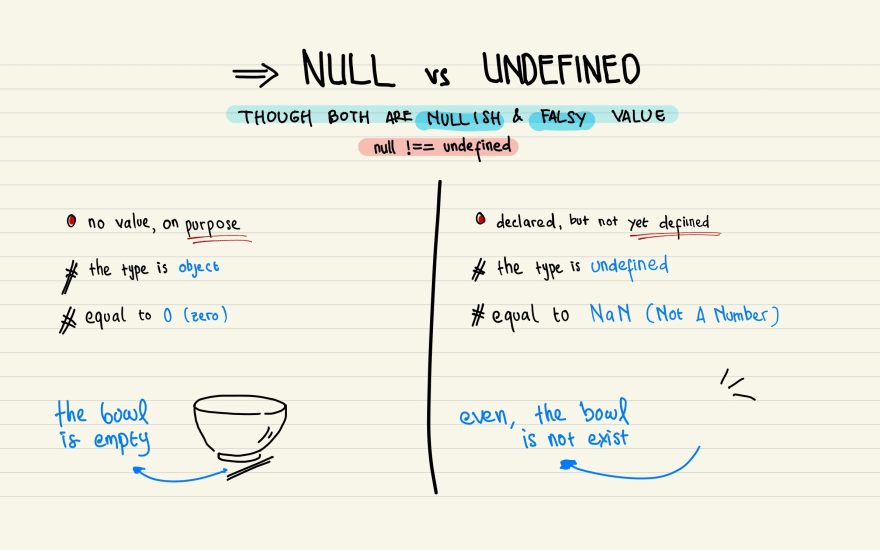
null 和 undefined 在 JavaScript 是最常见的空问题。 null 和 undefined 的定义 JavaScript 的最初版本是这样区分的: null是一个表示"无"的对象,转为数值时为 0; undefined是一个表示"无"的原始值,转为数值时为NaN。 下图对上面的 2 个概念进行了对比: 为什么会出现这个问题 这个和 JavaScript 的语言特性有关。 在最开始的时候,JavaScript 通常会被定义为是一个解释型语言。这个语言的特点是不需要编译,直接解释使用。 同时 JavaScript 为了增强语言的灵活性,又被设计为弱类型语言。 换句话说,在上面的定义的 null 的时候,是可以直接对应整数类型的,这个就对代码在执行的时候带来很多困惑。 针对编译类型和强类型语言来说,这个就非常头疼。 比如说在 Java 中,如果你需要使用一个字符串 string 之前,你必须要先定义这个字符串,你可以给字符串赋 null ,或者初始化一些字符,但是你必须要定义。 否则在后面引用的时候就会报错,JavaScript 就不需要这样,直接用就行,这个时候,如果你压根就没有定义一个变量,然后就直接用,那么就会出现 undefined 的错误。 在强类型语言中,如果你定义变量为字符串,那么你就只能往这个变量里面存字符串,如果你存其他类型的话,编译器会报错。JavaScript 会尝试自动给你类型转换,这个就带来不少困惑的问题,比如说在变量中存的 1 ,这个可能是整数 1 ,也可能是布尔类型。 如何判断 可以使用 _.isNil() 函数来进行判断。 检查 value 是否是 null 或者 undefined。 需要注意的是,如果你的输入值是 '' 的话,这个函数是没有办法判断的。 https://www.ossez.com/t/javascript-null-undefined/13693
考察下面的一个实例: const array1 = [1, 4, 9, 16]; // pass a function to map const map1 = array1.map(x => x * 2); console.log(map1); // expected output: Array [2, 8, 18, 32] 在上面的方法中,返回了一个对数组 map 后的结果。 方法解读 map() 方法返回一个新数组,数组中的元素为原始数组元素调用函数处理后的值。 map() 方法按照原始数组元素顺序依次处理元素。 map() 不会对空数组进行检测,map() 也不会改变原始数组。 从理解的角度来说就是 map() 方法会对原数组中的方法进行一次遍历,在遍历的时候,每次会取出原数组中的值,然后将取出来的值进行计算。 如何进行计算,取决于 map 函数内定义的方法,如果上面的示例,使用的是箭头表达式来进行计算的,如果你对箭头表达式还不太清楚的话,请参考相关文章。 当然,我们还可以在 map 中定义一个函数,例如下面的代码: const numbers = [65, 44, 12, 4]; const newArr = numbers.map(myFunction) function myFunction(num) { return num * 10; } 针对上面的这个代码就是在 map 方法执行的时候,将会从原始数组 numbers 内取得一个值(value),然后把这个值作为参数传递给 myFunction 这个函数。 myFunction 进行计算后,将返回的值填充回需要返回的数组中已经取出来的的值所对应的位置。 针对这个方法,我们只需要知道,需要对输入数组中的每一个只进行函数定义中的运算即可。 https://www.ossez.com/t/javascript-array-map/13692
在很多项目中,你可能会看到下面的一个函数。 _.each([1, 2], function(value) { console.log(value); }); 然后是不是非常困惑这是干什么的对吗? 然后从再到页面最上面看看,你可能会看到下面的这句话: import * as _ from 'lodash'; Lodash 库 上面的这句话就表示的是你的项目中使用 Lodash 这个库。 Lodash 是一个一致性、模块化、高性能的 JavaScript 实用工具库。 简单来说,这个库和 JQuery 差不多的一个意思,JQuery 通常能够让你能够更快对 HTML 中的元素进行选择,大家都知道 Jquery 的默认调用函数使用的是 $。 Lodash 能够对你需要的数据类型进行一些快速的操作,官方网站的地址为:https://lodash.com/ 。 例如上面的代码,你可以对一个数组进行一个遍历,直接使用函数就可以了。 否则的话,你可能需要自己写一个 for,看起来是不是有点麻烦。 Lodash 能够简化很多的操作,你也可以通过官方网站对已有的方法进行搜索。 通常,官方提供了一些示例,但是你可能还需要针对自己的数据,进行具体的调试。 https://www.ossez.com/t/lodash/13691
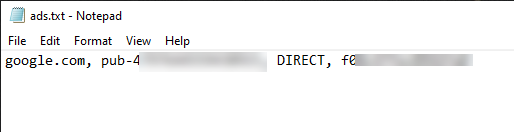
如果你希望在 Discourse 中设置 Google 的广告服务的话,Google 通常会要求你设置一个 ads.txt 文件。 这个文件的内容大致为下图的这种格式: 如何在 Discourse 中进行设置呢? 问题解决 其实 Discourse 已经帮你设置好了这个功能。 你只需要拷贝上面文本中的内容,然后中 Discourse 的控制台中选择 Ad Plugin 服务。 将内容拷贝到上面的文本框中,就可以完成有关广告的配置了。 通常来说广告服务商还需要等一段时间才能让配置识别,这个时候通常你不需要做任何修改。 还有一个办法就是通过网站的域名,直接访问 /ads.txt 这个文件,如果没有提示 404 错误的话,就说明已经配置成功了。 https://www.ossez.com/t/discourse-google-ads-txt/13690
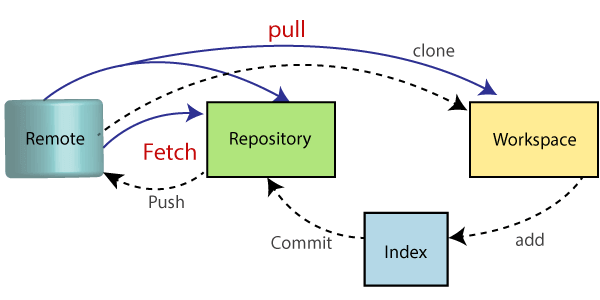
如果使用 Git 的话,这 2 个命令可能每天都要用几百遍。 相信绝大部分的人都会直接 pull,偶尔 fetch。但是这 2 个到底有什么不同呢? 不打算讨论过多的理论,因为非常枯燥,并且知道了可能也是看得迷迷糊糊。下面就使用场景来说。 应该用 Fetch 还是 Pull 应该 Pull 是绝大部分的情况。 针对 Git 使用的是分支管理代码,可以这样理解,在你对你的分支进行 Pull 之前,Git 就会 fetch 一下,当然这个 Fetch 只 Fetch 你的分支,如果你还需要看看其他的分支的话,那么你最好执行下 Fetch 命令。 举个栗子的使用场景,下面的流程可能是大部分人常用的流程。 你现在在处理你的分支称为 ci,项目的主分支是 master。 很多情况你可能是直接 pull 你的分支 ci,在这个时候 fetch 是被执行了。如果你要查看你本地 master 分支的话,那么你切换分支后需要再 pull 一下。 如果你对整个项目 fetch 的话,你就不需要再 pull 了。 因为很多公司的项目规范中不允许对 master 直接提交修改,必须使用 PR 的方式合并到 master,如果你的公司没有这个使用规范的话,那你就记得没事多从 远程 Master 合并下到你本地,没事多 fetch 下吧。 可以理解的就是 fetch 就是把本地仓库和远程仓库同步下,把远程仓库中的修改拉到你本地仓库里面来,但是不会做任何操作。 所以,通常的操作就是当你的分支 ci 里面辛苦工作的时候,只要不切换分支,你就大胆 pull 吧。 有人修改了你的分支 通常我们不是一个人工作,这个时候你遇到了一个非常困难的问题,幸好项目组里面有个大神帮你改了。 这个时候他会把他修改的内容 Push 到你的分支 ci 里面。 你需要看看这个大神改了什么,你可以做是直接 pull 就好了,然后在提交日志中看看他改了什么。 因为 pull 会涉及合并(merge)这个时候可能会出现冲突。 如果出现冲突的话,你就需要手动合并冲突后再提交。 这个使用场景是很多人都会遇到的。 从 master 上 pull 通常 master 都是主分支,有些项目会有 dev ,或者不同的供 CI 的分支。 有时候这些分支上面的修改你需要合并到你正在开发的分支上。 这个时候你就可以使用 Pull from 远程的分支到你本地了。在这个命令执行之前也会 fetch。 IJ 提供了 2 个选项,你可以选择 Rebase 也可以选择 Merge。 这个功能能够让你的分支和 Master 上的分支保持一致,能够避免在合并的时候出现很多意想不到的麻烦和冲突。 总结 在 Pull 之前会执行 Fetch,但是这个 Fetch 可能只 Fetch 你当前的分支。 如果你希望你的本地仓库和远程保持一致的话,你就单独执行下 Fetch ,避免在本地合并的时候丢数据。 在对项目从本地进行任何合并之前,记得都先 Fetch 下你的整个项目。 另外早上到公司后打开 IJ 在准备咖啡或者泡茶的时候,没啥事的话就先 pull 下你的分支,然后 fetch 下整个项目,然后开始愉快的一天。 https://www.ossez.com/t/git-fetch-pull/13689

ISO-8601 是国际标准化组织提供的一个有关时间表示的规范。 如下: 1970-01-01T00:00:00Z 可能是我们最常看到的格式了,这个表示的是一个 Epoch 时间,其实也不完全一定是,因为在上面没有表示出毫秒。 关于上面的时间格式解读如下: T 为日期和时间的分隔符,无特殊意义,猜测可能使用了英文单词 time 的首字母 T 吧。 Z 表示的是时区。应该取的是 Zone 的首字母,如果你看见表示的格式有 Z 的话,那么就说明当前的时间是 UTC 时间。 格式扩展 完整的 ISO 8601 可以用下面的格式来表示 2021-08-13T14:20:18.992847200-04:00 在上面的格式中的 字母 T 请参考前面的解释。 无字母 Z,如果没有字母 Z的话,应该使用的是 + 或者 - 符号,+ 表示的是东,比如说北京, - 表示的是 西部,比如 -04:00 表示的是西 5 区的美国东部时间。 在秒后面使用 点号 . 例如 上面的 .992847200 来表示纳秒,这个时间是可以省略的。 其实上面的时间格式都是可以进行格式化,取部分数据,或者省略掉数据,如果省略的数据在初始化的时候就被填充 0 。 Epoch 时间 纪元(Epoch)是指具有历史意义的某一刻,其实就是一个参考点。 Unix 纪元是 Unix 或类 Unix 系统,一些C/C++,Java等编程语言使用的纪元,从1970年一月一日00:00 开始。而其他的操作系统或者编程语言,使用的就是不一样的纪元起始日期了,比如 Microsoft C/C++ 7.0 使用的是 1899年12月31日。 从 Unix 纪元(1970-01-01-00:00:00)就是Unix时间的零点,以后的时间是正的,而 Unix 纪元之前的时间就是负值。 为什么 Unix 系统中纪元的时间是 1970 年 这个问题得去问 Unix 之父:Ken Thompson 和 Dennis Ritchie了,是他们选择这个时间作为 Unix 系统的纪元时间的。 第一版的 Unix 程序员手册是 1971年11月份出版的,上面定义Unix时间是:从1971年1月1日00:00:00开始,单位是一秒的六十分之一。 这意味在Unix时间的最早版本中,时间计数器以 60Hz 的频率(芯片的振荡器频率)递增,每隔 1/60 秒,计数器就加一。当时使用的整数计数器是 32 位的,这样 Unix 时间能够表示的范围就非常受限了,2^32/60/3600/24/30/12 大约是 2.3年。 所以后来经过多次更改,频率变成了1Hz,纪元时间改为了 1970年1月1日00:00:00。 有一种说法是Unix 操作系统诞生于 1970 年,但实际上并不是的,在 1969 年左右,Unix的概念就已经诞生了,Unix 的最早版本已经诞生了。Wired 网站上的一篇文章写道:Ritchie 说这个时间其实是随意选择的,因为需要一个统一的日期来作为时间的起点,而1970年的元旦,看起来是最方便的。 2038 年问题 2038 年问题又叫 Unix 千年臭虫或 Y2K38 错误。在时间值以带符号的 32 位整数来存储或计算的数据存储情况下,这个错误就有可能引发问题。 可以用 Unix 带符号的 32 位整数时间格式来表示的最新时间是 2038年1月19日03:14:07UTC,这是1970年1月1日之后过了2147483647秒。过了那个时间后,由于整数溢出,时间值将作为负数来存储,系统会将日期读为1901年12月13日,而不是2038年1月19日。 用简单的语言来说,Unix机器最终将会耗尽存储空间来列举秒数。所以,到那一天,使用标准时间库的C 程序会开始出现日期问题。 其实就是因为整数的最大计数在这一天会溢出,导致无法正确处理时间。 感觉人类文明就是和时间和存储过不去。 https://www.ossez.com/t/iso-8601/13687
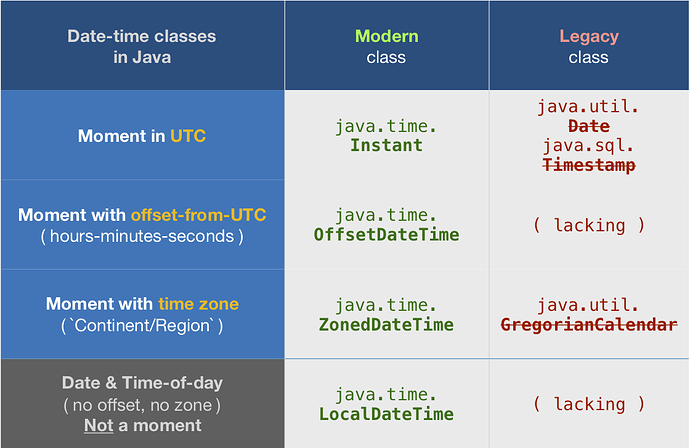
因为众所周知的原因,老的 Java 中的日期处理是非常不好用但是又不得不用的 API。 而且经常混乱还容易出错,相信大家应该都用过救民于水火的 joda Datetime 对象吧,简直是活菩萨。 时间来到 JDK 8 以后的版本了,我们还需要使用 joda 吗? 结论 根据官方的说法,joda 项目已经不再积极维护了。 Joda-time is no longer in active development except to keep timezone data up to date. From Java SE 8 onwards, users are asked to migrate to java.time (JSR-310) - a core part of the JDK which replaces this project. 上面的原文就是 Joda 已经不再积极进行开发了,只是进行一些时区数据的维护了。 所有的功能你应该都可以使用 java.time 来实现了。 简单来说就是如果你使用的是 JDK 8 以后的版本,你可以慢慢将 Joda 从你的项目中移除了,如果你还使用的是早期的版本,那么你还是需要导入的。 从官方的代码来看,也已经超过有 1 年多没有提交任何代码了。 还是感觉有点遗憾的,可能很多人都已经习惯 DateTime 来 new 一下然后进行一堆计算。 使用体验 针对 JDK 的 java.time 如果你需要获得当前的时间。 Date-Time API 的核心类之一是 Instant 类,它表示时间轴上的纳秒开始。 Instant 类返回的值计算从 1970 年 1 月 1 日(1970-01-01T00:00:0Z)第一秒开始的时间, 也称为 EPOCH。 发生在时期之前的瞬间具有负值,并且发生在时期后的瞬间具有正值。 Instant 不包含年,月,日等单位。但是可以转换成 LocalDateTime 或 ZonedDateTime, 如下 把一个 Instant + 默认时区转换成一个 LocalDateTime。 无论是 ZonedDateTime 或 OffsetTimeZone 对象可被转换为 Instant 对象,因为都映射到时间轴上的确切时刻。 但是,相反情况并非如此。 要将 Instant 对象转换为 ZonedDateTime 或 OffsetDateTime 对象,需要提供时区或时区偏移信息。 我们可以考察下面的这些代码片段: Instant instant = Instant.now(); System.out.println("------"); System.out.println(instant.toString()); System.out.println(instant.truncatedTo(ChronoUnit.SECONDS).toString()); System.out.println(instant.toString()); ZonedDateTime zonedDateTime = ZonedDateTime.now(); System.out.println("------"); System.out.println(zonedDateTime.toString()); System.out.println(zonedDateTime.toInstant().toString()); Date date = new Date(); System.out.println("------"); System.out.println(date.toString()); System.out.println(date.toInstant().toString()); 对应的输出为: ------ 2021-08-13T18:20:18.977845200Z 2021-08-13T18:20:18Z 2021-08-13T18:20:18.977845200Z ------ 2021-08-13T14:20:18.992847200-04:00[America/New_York] 2021-08-13T18:20:18.992847200Z ------ Fri Aug 13 14:20:18 EDT 2021 2021-08-13T18:20:18.993Z 针对上面的理解是,Instant 对象获得是当前的 UTC 时间,在这个时间中如果你不希望显示毫秒的话,你可以使用 truncatedTo 方法来格式化显示。 Instant 类是 immutable (不可变)的,因此就算你 truncatedTo 过后也不可以改变 Instant 对象。除非你重新 new 一个。 使用 ZonedDateTime 创建一个对象和 Date 创建一个对象是一样的,都是获得当前时区的时间。 例如我们现在是在美国东部时间,那么上面 2 个对象将会获得当前计算机的时间,同时上面 2 个对象还提供了 toInstant() 方法,这个方法将会显示当前时间对应的 UTC 时间。 从输出就可以看出来。 具体的一些转换我们在后续的学习文章中再逐步列出。 进行一些总结就是: Instant 在 new 了以后是不可变的,总是指向 UTC 的时间。 如果需要转换带有时区的本地时间,那么需要在转换的时候添加时区偏移量。 Date 和 ZonedDateTime 创建的时间为带有时区的本地计算机的时间。 Date 和 ZonedDateTime 都可以转换为 Instant,不需要添加时区偏移量。 https://www.ossez.com/t/java-joda/13686
英文标题【Array to String Conversions】 概述 本页面中的内容对 Array 和 String 之间互相进行转换的方法进行一些说明。 我们可以使用 原生 Java(vanilla Java) 或者一些第三方的 Java 工具类来实现这个转换。 将 Array 转换为 String 在有时候我们希望将字符串的数字或者整数类型的数组转换为字符串。但是如果我们直接使用 toString() 来进行转换的话,你可能会得到类似下面 Ljava.lang.String;@74a10858 的字符串。 上面的字符串显示的是对象的类型和当前这个对象的哈希代码。 但是, java.util.Arrays 工具类也能够支持一些 toString() 的方法来将 Array 转换为 String。 Arrays.toString() 将输入的数组转换为字符串,在转换后的字符串将会使用逗号分隔符,同时在字符串的前后会添加一个方括号 []。 可以考察下面的代码: String[] strArray = {"one", "two", "three"}; String joinedString = Arrays.toString(strArray); assertEquals("[one, two, three]", joinedString); int[] intArray = {1, 2, 3, 4, 5}; joinedString = Arrays.toString(intArray); assertEquals("[1, 2, 3, 4, 5]", joinedString); StringBuilder 的 append() 方法 这个是基于 Java 的原生实现,你可以对需要转换的数组进行遍历,然后将遍历的结果使用 append() 方法添加到字符串后面。 String[] strArray = {"Convert", "Array", "With", "Java"}; StringBuilder stringBuilder = new StringBuilder(); for (int i = 0; i < strArray.length; i++) { stringBuilder.append(strArray[i]); } String joinedString = stringBuilder.toString(); assertEquals("ConvertArrayWithJava", joinedString); 另外,如果你的数组中存储的数据是整形的话,那么你可以使用方法转换函数,首先将整数类型转换为字符串后再添加。 Java Streams API 从 Java 8 及其以上的版本,你可以使用 String.join() 方法将给出的数组元素使用不同的连接字符串连接在一起,在我们使用案例中,我们使用空白字符进行连接。 String joinedString = String.join("", new String[]{"Convert", "With", "Java", "Streams"}); assertEquals("ConvertWithJavaStreams", joinedString); 更多的是,我们可以使用 Java Streams API 中的 Collectors.joining() 方法来进行连接,这个连接的方法将会保留和输入数据相同的顺序。 String joinedString = Arrays .stream(new String[]{"Convert", "With", "Java", "Streams"}) .collect(Collectors.joining()); assertEquals("ConvertWithJavaStreams", joinedString); StringUtils.join() Apache Commons Lang 为字符串处理提供了非常好的方法,能够很好的帮我们解决上面的问题。 这个 join 的方法可以通过输入的数据进行自动进行合并,合并的结果与你输入数据的顺序相同。 String joinedString = StringUtils.join(new String[]{"Convert", "With", "Apache", "Commons"}); assertEquals("ConvertWithApacheCommons", joinedString); Joiner.join() 同样的 Guava 也提供了同样的工具类来使用。 例如,我们可以使用下面的代码来对数组进行连接。 String joinedString = Joiner.on("") .skipNulls() .join(new String[]{ "Convert", "With", "Guava", null }); assertEquals("ConvertWithGuava", joinedString); 将字符串转换为数组 同样的,在有些时候,我们希望能够将字符串转换为数组。 最常用的情况就是有一个输入的字符串,使用特定的分隔符,我们需要按照分隔符的位置将字符串拆分为数组。 String.split() 这个是最简单的方法了,可以直接把字符串中的字符使用给定的字符进行拆分,如下面的代码: String[] strArray = "loremipsum".split(""); 上面的代码将会生成下面的输出,因为我们没有给定任何分隔符,所以这个方法将会按照字符进行拆分。 ["l", "o", "r", "e", "m", "i", "p", "s", "u", "m"] StringUtils.split() 另外,可能用得最多的就是 Apache 的 Commons 中的 StringUtils ,这个能够对指定的字符串进行拆分。 如果使用 String 的方法进行拆分的话,可能会遇到空对象的问题,例如你输入的字符串可能是空字符串,这个时候 String 自带的原生方法将会抛出空异常。 如果使用 StringUtils 方法的话,可以有效的避免空对象的异常,因此这个工具类是非常常用的。在默认的情况下,这个方法使用的是空格作为分隔符。 String[] splitted = StringUtils.split("lorem ipsum dolor sit amet"); 上面的方法将会输出下面的数组。 ["lorem", "ipsum", "dolor", "sit", "amet"] Splitter.split() 最后,你还可以使用 Guava 的拆分 API,如果 Apache Commons 提供的方法,通常 Guava 也能提供类似的。 例如我们可以使用下面的方法进行拆分,可以看到的是,我们在拆分的时候可以同时对结果进行处理。 List<String> resultList = Splitter.on(' ') .trimResults() .omitEmptyStrings() .splitToList("lorem ipsum dolor sit amet"); String[] strArray = resultList.toArray(new String[0]); 上面的代码能够生成下面的结果: ["lorem", "ipsum", "dolor", "sit", "amet"] 结论…
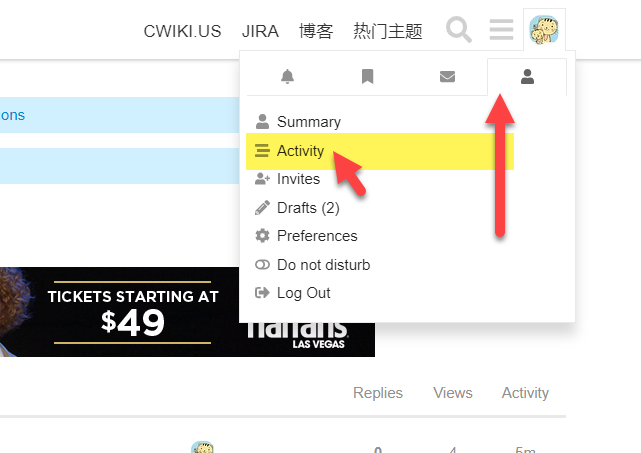
有朋友问,如何在 Discourse 中查看自己的主题,以便于对自己发布的主题进行修改。 这个主要是在我们其中一个供客户发布租房信息的网站上面。 进入路径 其实是可以从你的用户的头像中进入的。 在页面的左上角选择你的用户头像,然后进行单击。然后选择最右侧的图标下面的活动。 如下图: 然后可以从左侧导航进行查看自己发布的内容。 如果你在一个网站上面发布的内容比较多的话,那么可能还只能通过主题搜索功能更加好一些。 在列表中,你还可以看到你的内容的被访问的数量,来了解你发布的内容的活跃程度。 https://www.ossez.com/t/discourse/13684