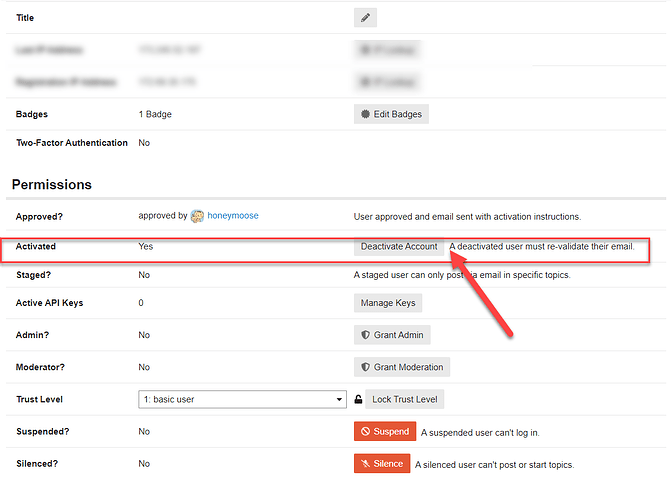
Discourse 对邮件的依赖程度是非常高的。 通常来说用户可能会因为你的网站发送邮件过多而拒收,这个时候如果你使用的是第三方的邮件服务器的话,通常在日志上会显示拒绝。 对拒绝的邮件我们通常还是希望留住这个用户不要删除。 根据 Discourse 的后台,我们考古后发现有一个 Deactivate Account 功能。 这个功能应该对用户进行取消激活,用户就收不到电子邮件了,但是用户的数据还是在网站上的,用户还可以继续激活邮件后使用。 这个应该是比较好的解决方案。 不知道还有没有其他的解决方案?可以供选择? https://www.ossez.com/t/discourse/13683
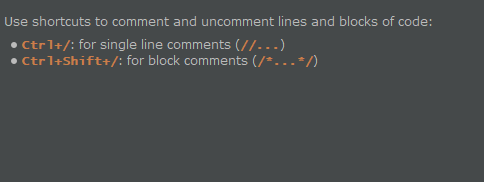
Java 的注释有 2 种 //. 和 /*...*/ IntelliJ IDEA 可以使用下面的快捷键来对代码进行注释: Ctrl+/: for 单行注释 (//…) Ctrl+Shift+/: 块注释 (/…/) Java 注释类型 如果你对上面的所谓单行注释和块注释不明白的话。 就看看下面的图就好了: 通常在 IDE 中,不同的注释类型颜色也是不一样的。 灰色的是行注释。 在这里有一个小技巧是,如果你想一次连续注释多行的话,你不需要每一行每一行的选择。。 可以一次选择后使用快捷键注释掉。 如下图显示一次性注释掉多行。 如果需要取消连续行的注释的话,就选择已经注释掉的行,再次输入 Ctrl+/ 就可以了。 上面图显示的是快注释中的前后。 在第一张大图中,显示的通常是在 Java 中作为文档来使用的。 大部分情况下,使用行注释的可能频率更高一些。 https://www.ossez.com/t/intellij-idea-java/13681
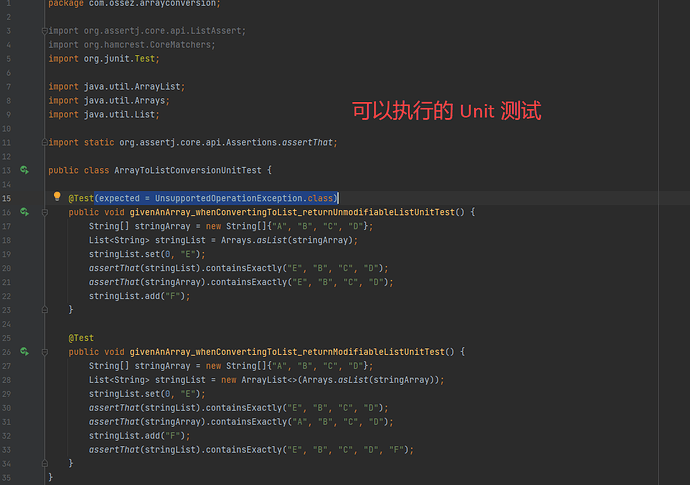
英文标题【Arrays.asList vs new ArrayList(Arrays.asList())】 概述 在本文章中,我们会对 Arrays.asList(array) 和 ArrayList(Arrays.asList(array)) 之间的区别进行一些对比。 Arrays.asList 首先我们对 Arrays.asList 方法进行一些查看和说明。你可以单击上面的链接查看官方的 API。 通过 API 的文档我们可以了解到,使用这个方法将会为数组创建一个固定长度(fixed-size)List 对象。这个方法只是对 array 数组进行了一次包装,以便于在程序中可以使用 List,在这个包装中没有数据被拷贝或者创建。 同时,我们也不能对新创建的 List 的长度进行修改,因为添加或者删除 List 中的元素是不被允许的。 然而,我们是可以对新创建的 List 中的数组中的元素进行修改的。需要注意的是,如果你对 List 中的元素数据进行了修改的话,那么对应 Array 的数据也被改动了。 例如,考察下面的代码,我们首先创建了一个数组,然后将数组包装成了 List ,然后我们再对包装成 List 后的一个元素进行了修改。 String[] stringArray = new String[]{"A", "B", "C", "D"}; List<String> stringList = Arrays.asList(stringArray); 现在我们对包装后的的 List 的一个元素进行修改。 stringList.set(0, "E"); assertThat(stringList).containsExactly("E", "B", "C", "D"); assertThat(stringArray).containsExactly("E", "B", "C", "D"); stringList.add("F"); 从输出中,我们可以看到,我们修改 List 后,原始的 Array 也被修改了。 现在我们 List 和 Array 中的元素和顺序都是完全一样的。 现在我们尝试向包装后的 stringList 中插入一个新的元素。 stringList.add("F"); 抛出的异常: java.lang.UnsupportedOperationException at java.base/java.util.AbstractList.add(AbstractList.java:153) at java.base/java.util.AbstractList.add(AbstractList.java:111) 通过上面的代码我们可以看到,这个时候如果你对 List 进行元素插入或者删除的时候,程序将会抛出 java.lang.UnsupportedOperationException 异常。 ArrayList(Arrays.asList(array)) 与 Arrays.asList 方法一样,我们还可以使用 ArrayList<>(Arrays.asList(array)) 来从 Array 创建一个 List。 但是,与上面的方法不一样的是,使用这个方法创建的 List 是一个从老的 Array 中数据拷贝过来的,这个新的 List 与老的 Array 不相干,对新 List 中数据的操作不会影响到老的 Array 中的数据。 换句话说,使用这种方法创建的 List 是可以对 List 中的元素进行添加和删除操作的。 String[] stringArray = new String[]{"A", "B", "C", "D"}; List<String> stringList = new ArrayList<>(Arrays.asList(stringArray)); 现在我们对创建后的新 List 中的一个元素进行修改操作。 stringList.set(0, "E"); assertThat(stringList).containsExactly("E", "B", "C", "D"); 现在,我们再查看下 List 和 Array 数据中的区别。 assertThat(stringArray).containsExactly("A", "B", "C", "D"); 从上面的输出可以看到,老的 Array 中的数据没有被修改。 你可以访问 JDK source code 中的内容查看下源代码。 我们可以从源代码中看到 Arrays.asList 返回 ArrayList 的类型和 从 java.util.ArrayList 中返回的类型是不一样的。 主要的不同就是 Arrays.asList 返回的 ArrayList 只对老的 Array 进行了包装,没有实现 add 和 remove 方法。 结论 本文章中的实验主要对上面 2 种将数组转换为 List 的方法进行了对比。 主要不同的地方就是在于是否能够对转换后的数组进行元素的添加和删除等常规操作。 https://www.ossez.com/t/java-arrays-aslist-new-arraylist-arrays-aslist/13680
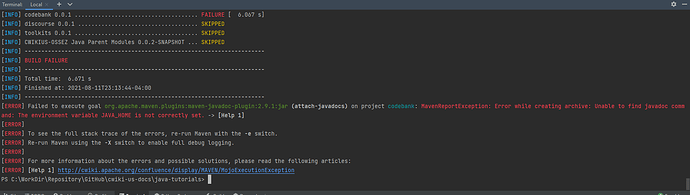
提示的错误信息如下: [ERROR] Failed to execute goal org.apache.maven.plugins:maven-javadoc-plugin:2.9.1:jar (attach-javadocs) on project codebank: MavenReportException: Error while creating archive: Unable to find javadoc command: The environment variable JAVA_HOME is not correctly set. -> [Help 1] [ERROR] [ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch. [ERROR] Re-run Maven using the -X switch to enable full debug logging. [ERROR] [ERROR] For more information about the errors and possible solutions, please read the following articles: [ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/MojoExecutionException 如下图: 问题和解决 上面的提示已经比较清楚了。 你没有在你的环境变量中设置 JAVA_HOME 需要按照上面的设置一个环境变量。 如果你使用的是 IEDA 的话,你需要重启的 IDEA 环境。 如果你使用的是命令行工具的话,你也需要退出后重启。 然后再次进行编译,应该就能解决上面的问题了。 https://www.ossez.com/t/maven-java-home-is-not-correctly-set/13679
tuningConfig 的配置是可选的,如果你不在这里对这个参数进行配置的话,Druid 将会使用默认的配置来替代。 5-Best-Practices-for-Proactive-Database-V21500×700 15.5 KB 字段(Field) 类型(Type) 描述(Description) 是否必须(Required) type String 索引任务类型, 总是 kafka。 Y maxRowsInMemory Integer 在持久化之前在内存中聚合的最大行数。该数值为聚合之后的行数,所以它不等于原始输入事件的行数,而是事件被聚合后的行数。 通常用来管理所需的 JVM 堆内存。 使用 maxRowsInMemory * (2 + maxPendingPersists) 来当做索引任务的最大堆内存。通常用户不需要设置这个值,但是也需要根据数据的特点来决定,如果行的字节数较短,用户可能不想在内存中存储一百万行,应该设置这个值。 N(默认=1000000) maxBytesInMemory Long 在持久化之前在内存中聚合的最大字节数。这是基于对内存使用量的粗略估计,而不是实际使用量。通常这是在内部计算的,用户不需要设置它。 索引任务的最大内存使用量是 maxRowsInMemory * (2 + maxPendingPersists) N(默认=最大JVM内存的 1/6) maxRowsPerSegment Integer 聚合到一个段中的行数,该数值为聚合后的数值。 当 maxRowsPerSegment 或者 maxTotalRows 有一个值命中的时候,则触发 handoff(数据存盘后传到深度存储), 该动作也会按照每 intermediateHandoffPeriod 时间间隔发生一次。 N(默认=5000000) maxTotalRows Long 所有段的聚合后的行数,该值为聚合后的行数。当 maxRowsPerSegment 或者 maxTotalRows 有一个值命中的时候,则触发handoff(数据落盘后传到深度存储), 该动作也会按照每 intermediateHandoffPeriod 时间间隔发生一次。 N(默认=unlimited) intermediatePersistPeriod ISO8601 Period 确定触发持续化存储的周期 N(默认= PT10M) maxPendingPersists Integer 正在等待但启动的持久化过程的最大数量。 如果新的持久化任务超过了此限制,则在当前运行的持久化完成之前,摄取将被阻止。索引任务的最大内存使用量是 maxRowsInMemory * (2 + maxPendingPersists) 否(默认为0,意味着一个持久化可以与摄取同时运行,而没有一个可以进入队列) indexSpec Object 调整数据被如何索引。详情可以见 IndexSpec 页面中的内容 N indexSpecForIntermediatePersists 定义要在索引时用于中间持久化临时段的段存储格式选项。这可用于禁用中间段上的维度/度量压缩,以减少最终合并所需的内存。但是,在中间段上禁用压缩可能会增加页缓存的使用,而在它们被合并到发布的最终段之前使用它们,有关可能的值。详情可以见 IndexSpec 页面中的内容。 N(默认= 与 indexSpec 相同) reportParseExceptions Boolean 已经丢弃(DEPRECATED)。如果为true,则在解析期间遇到的异常即停止摄取;如果为false,则将跳过不可解析的行和字段。将 reportParseExceptions 设置为 true 将覆盖maxParseExceptions 和 maxSavedParseExceptions 的现有配置,将maxParseExceptions 设置为 0 并将 maxSavedParseExceptions 限制为不超过1。 N(默认=false) handoffConditionTimeout Long 段切换(持久化)可以等待的毫秒数(超时时间)。 该值要被设置为大于0的数,设置为0意味着将会一直等待不超时。 N(默认=0) resetOffsetAutomatically Boolean 控制当Druid需要读取Kafka中不可用的消息时的行为,比如当发生了 OffsetOutOfRangeException 异常时。 如果为false,则异常将抛出,这将导致任务失败并停止接收。如果发生这种情况,则需要手动干预来纠正这种情况;可能使用 重置 Supervisor API 。此模式对于生产非常有用,因为它将使您意识到摄取的问题。如果为true,Druid将根据 useEarliestOffset 属性的值(true 为 earliest ,false 为 latest )自动重置为Kafka中可用的较早或最新偏移量。请注意,这可能导致数据在您不知情的情况下被丢弃 (如果useEarliestOffset 为 false )或 重复 (如果 useEarliestOffset 为 true )。消息将被记录下来,以标识已发生重置,但摄取将继续。这种模式对于非生产环境非常有用,因为它将使Druid尝试自动从问题中恢复,即使这些问题会导致数据被安静删除或重复。该特性与Kafka的 auto.offset.reset 消费者属性很相似 N(默认=false) workerThreads Integer supervisor 用于为工作任务处理 请求/相应(requests/responses)异步操作的线程数。 N(默认=min(10, taskCount)) chatThreads Integer 与索引任务的会话线程数。 N(默认=10, taskCount * replicas)) chatRetries Integer 在任务没有响应之前,将重试对索引任务的HTTP请求的次数 N(默认=8) httpTimeout ISO8601 Period 索引任务的 HTTP 响应超时的时间。 N(默认=PT10S) shutdownTimeout ISO8601 Period supervisor 尝试无故障的停掉一个任务的超时时间。 N(默认=PT80S) offsetFetchPeriod ISO8601 Period supervisor 查询 Kafka 和索引任务以获取当前偏移和计算滞后的频率。 N(默认=PT30S,min == PT5S) segmentWriteOutMediumFactory Object 创建段时要使用的段写入介质。更多信息见下文。 N (默认不指定,使用来源于 druid.peon.defaultSegmentWriteOutMediumFactory.type 的值) intermediateHandoffPeriod ISO8601 Period 段发生切换的频率。当 maxRowsPerSegment 或者 maxTotalRows 有一个值命中的时候,则触发handoff(数据存盘后传到深度存储), 该动作也会按照每 intermediateHandoffPeriod 时间间隔发生一次。 N(默认=P2147483647D) logParseExceptions Boolean 如果为 true,则在发生解析异常时记录错误消息,其中包含有关发生错误的行的信息。 N(默认=false) maxParseExceptions Integer 任务停止接收之前可发生的最大分析异常数。如果设置了 reportParseExceptions ,则该值会被重写。 N(默认=unlimited) maxSavedParseExceptions Integer 当出现解析异常时,Druid可以跟踪最新的解析异常。"maxSavedParseExceptions"决定将保存多少个异常实例。这些保存的异常将在 任务完成报告 中的任务完成后可用。如果设置了reportParseExceptions ,则该值会被重写。 N(默认=0) https://www.ossez.com/t/druid-kafka-tuningconfig/13672
下面的表格主要对加载 Kafka 流数据的索引属性进行参数描述。 字段(Field) 类型(Type) 描述(Description) 是否必须(Required) bitmap Object 针对 bitmap indexes 使用的是压缩格式。应该是一个 JSON 对象,请参考 Bitmap types 来了解更多 N(默认=Roaring) dimensionCompression String 针对维度(dimension)列使用的压缩算法,请从 LZ4, LZF,或者 uncompressed 中选择。 N(默认= LZ4) metricCompression String 针对主要类型 metric 列使用的压缩算法,请从 LZ4, LZF,或者 uncompressed 中选择。 N(默认= LZ4) longEncoding String 类型为 long 的 metric 列和 维度(dimension)的编码格式。从 auto 或 long 中进行选择。auto 编码是根据列基数使用偏移量或查找表对值进行编码,并以可变大小存储它们。longs 将会按照,每个值 8 字节来进行存储。 N(默认= longs) https://www.ossez.com/t/druid-kafka-indexspec/13673
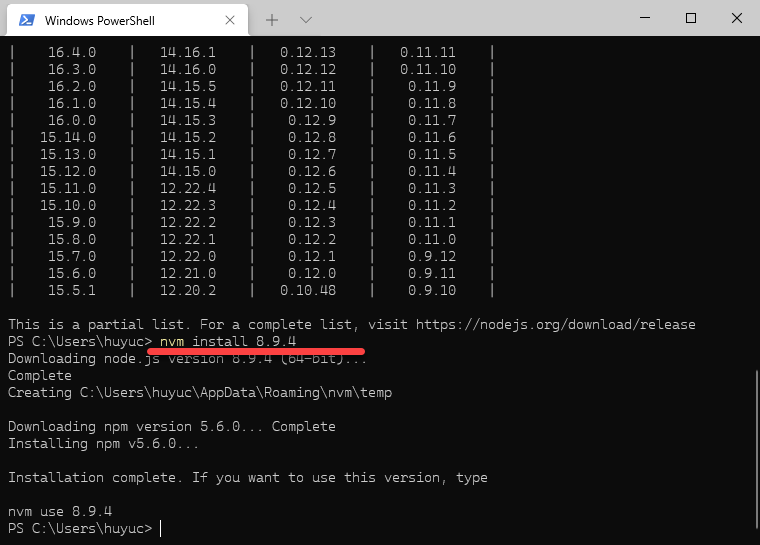
在使用 nvm 安装新的 nvm 版本之前,请确定你的操作系统中已经安装了 nvm。 安装的方法,请访页面:Windows 中 Node.js 中 nvm 的安装配置和使用 中的内容。 安装新版本 假设我们需要安装的新版本为 8.9.4,那么你需要执行命令 nvm install 8.9.4。 只需要等待一会就可以看到新的 nodejs 被安装成功了。 通过执行命令 nvm ls 来查看你的计算机中装了几个版本的 nodejs。 切换版本 对版本进行切换使用的命令为: nvm use 8.9.4 随后再可以使用 node -v 来查看当前系统中使用的 node 的版本。 至此,我们使用 nvm 对版本的安装和切换就已经完成了。 https://www.ossez.com/t/nvm-nodejs/13669
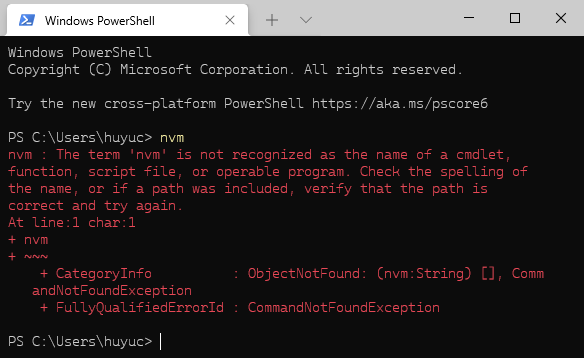
nvm 的安装还是比较简单的,主要是需要完成下载安装和路径配置即可。 首先可以使用命令 nvm 来查看当前系统中有没有安装 nvm。 下载安装 可以访问下面的地址来找到最新的 nvm 的安装版本: Releases · coreybutler/nvm-windows · GitHub 需要下载的程序通常为:nvm-setup.zip 下载完成后双击运行进行安装。 安装过程 下面对安装的过程进行一些说明和配置。 同意许可协议 选择安装路径 在安装的时候,使用默认的安装路径就可以了。 选择 nodejs 的安装路径 一般来说,我们都会使用默认安装,在这里也不需要进行修改。 安装摘要 显示已有的 nodejs 安装 在这里将会提示你是否使用 nvm 对已安装的 nodejs 进行配置。 如果需要的话,选择 Yes,通常我们选择 Yes 就好。 安装进程 安装过程很快,通常一会就能安装好了。 安装完成 如果能够看到下面的图片,就说明安装已经完成了。 单击完成退出安装程序。 校验安装 重新打开一个控制台工具,在控制台工具中输入命令 nvm ls,如果能够看到当前的 nodejs 版本的话,则说明 nvm 已经配置好了。 通常来说你并不需要主动将 nvm 的可执行文件添加到 path 路径中,如果这里你还提示没有可以执行的命令的话,你需要尝试退出下你的控制台,再次启动。 如果还有问题的话,请查看下你的 nvm 可执行文件是不是在你的 PATH 路径中。 查看可用的 nodejs 版本 执行命令:nvm ls available 能够查看可用的 nvm 版本。 然后你可以通过选择可用的版本进行安装。 https://www.ossez.com/t/windows-node-js-nvm/13668
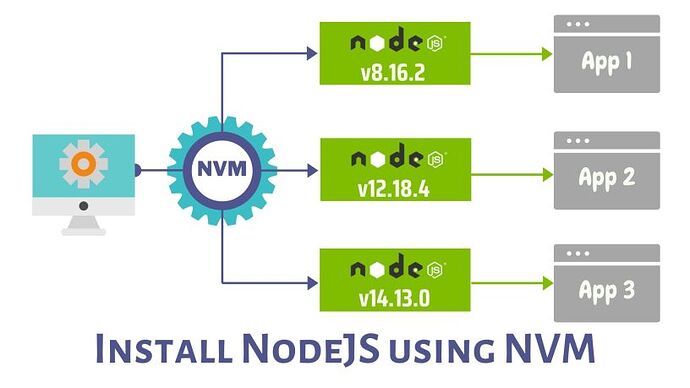
从字面上面就可以理解上面 2 个定义的不同。 如果要直接解释就是: Node.js:NodeJS 项目开发需要使用的解释器 npm:随着 Node.js 一同安装的包管理器(主要用来管理包)。 nvm:需要单独安装,主要对项目使用的 Node.js 解释器进行管理。 用土话说,因为有 P,所以管理包(Package),因为有 V,所以管理版本(V)。 但是 Node.js 又不自带版本管理器,因此需要一个其他的一个程序来管理,这个程序是需要安装的,这就是为什么 nvm 需要单独安装的原因了。 来源就是狗日的 Node.js 的版本迭代速度太快,加上 JS 使用的包管理器没有 maven 那么优雅,自然就会导致一套系统中部署不同的 Node.js 版本,更加讨厌的是各个版本直接还没有办法直接兼容。 那就需要开发人员不同的切换版本,nvm 就为了满足这个需求而存在的。 https://www.ossez.com/t/npm-nvm/13667

Kafka 索引服务(indexing service)支持 inputFormat 和 parser 来指定特定的数据格式。 inputFormat 是一个较新的参数,针对使用的 Kafka 索引服务,我们建议你对这个数据格式参数字段进行设置。 不幸的是,目前还不能支持所有在老的 parser 中能够支持的数据格式(Druid 将会在后续的版本中提供支持)。 目前 inputFormat 能够支持的数据格式包括有: csv, delimited, json。 如果你使用 parser 的话,你也可以阅读: avro_stream, protobuf, thrift 数据格式。 因为 Druid 的数据版本的更新,在老的环境下,如果使用 parser 能够处理更多的数格式。 如果通过配置文件来定义的话,在目前只能处理比较少的数据格式。 在我们的系统中,通常将数据格式定义为 JSON 格式,但是因为 JSON 的数据是不压缩的,通常会导致传输数据量增加很多。 如果你想使用 protobuf 的数据格式的话,能够在 Kafka 中传递更多的内容,protobuf 是压缩的数据传输,占用网络带宽更小。 在小型系统中可能不一定会有太大的问题,但是对于大型系统来说,如果传输量小 80% 的话,那占用网络带宽也会小很多,另外也能降低错误率。 https://www.ossez.com/t/druid-kafka/13666