可用的字段和配置信息,请参考表格。 需要注意的是配置的段的定义为为: ioConfig 字段(Field) 类型(Type) 描述(Description) 是否必须(Required) topic String 从 Kafka 中读取数据的 主题(topic)名。你必须要指定一个明确的 topic。例如 topic patterns 还不能被支持。 Y inputFormat Object inputFormat 被指定如何来解析处理数据。请参考 the below section 来了解更多如何指定 input format 的内容。 Y consumerProperties Map<String, Object> 传递给 Kafka 消费者的一组属性 map。这个必须包含有一个 bootstrap.servers 属性。这个属性的值为: <BROKER_1>:<PORT_1>,<BROKER_2>:<PORT_2>,... 这样的服务器列表。针对使用 SSL 的链接: keystore, truststore,key 可以使用字符串密码,或者使用 Password Provider 来进行提供。 Y pollTimeout Long Kafka 消费者拉取数据等待的时间。单位为:毫秒(milliseconds)The length of time to wait for the Kafka consumer to poll records, in N(默认=100)) replicas Integer 副本的数量, 1 意味着一个单一任务(无副本)。副本任务将始终分配给不同的 workers,以提供针对流程故障的恢复能力。 否(no)(默认值:1) taskCount Integer 在一个 replica set 集中最大 reading 的数量。这意味着读取任务的最大的数量将是 taskCount * replicas, 任务总数(reading + publishing)是大于这个数值的。请参考 Capacity Planning 中的内容。如果 taskCount > {numKafkaPartitions} 的话,总的 reading 任务数量将会小于 taskCount 。 N(默认=1)) taskDuration ISO8601 Period 任务停止读取数据并且将已经读取的数据发布为新段的时间周期 N(默认=PT1H) startDelay ISO8601 Period supervisor 开始管理任务之前的等待时间周期。 N(默认=PT1S) period ISO8601 Period supervisor 将要执行管理逻辑的时间周期间隔。请注意,supervisor 将会在一些特定的事件发生时进行执行(例如:任务成功终止,任务失败,任务达到了他们的 taskDuration)。因此这个值指定了在在 2 个事件之间进行执行的最大时间间隔周期。 N(默认=PT30S) useEarliestOffset Boolean 如果 supervisor 是第一次对数据源进行管理,supervisor 将会从 Kafka 中获得一系列的数据偏移量。这个标记位用于在 Kafka 中确定最早(earliest)或者最晚(latest)的偏移量。在通常使用的情况下,后续的任务将会从前一个段结束的标记位开始继续执行,因此这个参数只在 supervisor 第一次启动的时候需要。 否(no)(默认值: false) completionTimeout ISO8601 Period 声明发布任务为失败并终止它 之前等待的时间长度。如果设置得太低,则任务可能永远不会发布。任务的发布时刻大约在 taskDuration (任务持续)时间过后开始。 N(默认=PT30M) lateMessageRejectionStartDateTime ISO8601 DateTime 用来配置一个时间,当消息时间戳早于此日期时间的时候,消息被拒绝。例如我们将这个时间戳设置为 2016-01-01T11:00Z 然后 supervisor 在 2016-01-01T12:00Z 创建了一个任务,那么早于 2016-01-01T11:00Z 的消息将会被丢弃。这个设置有助于帮助避免并发(concurrency)问题。例如,如果你的数据流有延迟消息,并且你有多个需要在同一段上操作的管道(例如实时和夜间批处理摄取管道)。 N(默认=none) lateMessageRejectionPeriod ISO8601 Period 配置一个时间周期,当消息时间戳早于此周期的时候,消息被拒绝。例如,如果这个参数被设置为 PT1H 同时 supervisor 在 2016-01-01T12:00Z 创建了一个任务,那么所有早于 2016-01-01T11:00Z 的消息将会被丢弃。 个设置有助于帮助避免并发(concurrency)问题。例如,如果你的数据流有延迟消息,并且你有多个需要在同一段上操作的管道(例如实时和夜间批处理摄取管道)。请注意 lateMessageRejectionPeriod 或者 lateMessageRejectionStartDateTime 2 个参数只能指定一个,不能同时赋值。 N(默认=none) earlyMessageRejectionPeriod ISO8601 Period 用来配置一个时间周期,当消息时间戳晚于此周期的时候,消息被拒绝。例如,如果这个参数被设置为 PT1H,taskDuration 也被设置为 PT1H,然后 supervisor 在 2016-01-01T12:00Z 创建了一个任务,那么所有晚于 2016-01-01T14:00Z 的消息丢会被丢弃,这是因为任务的执行时间为 1 个小时,earlyMessageRejectionPeriod 参数的设置为 1 个小时,因此总计需要等候 2 个小时。 注意: 任务有时候的执行时间可能会超过任务 taskDuration 参数设定的值,例如,supervisor 被挂起的情况。如果设置 earlyMessageRejectionPeriod 参数过低的话,在任务的执行时间超过预期的话,将会有可能导致消息被意外丢弃。 N(默认=none) 如上面表格的配置信息,我们可以对 Kafka 中的配置进行一些调整来满足特定的项目消息需求。 如果你对需要调整的默认值不是非常了解和清楚的话,可以使用默认值,通常默认值不是最优的,但是可能是能够保障能正确工作的最低配置。 https://www.ossez.com/t/druid-kafka-kafkasupervisorioconfig/13665

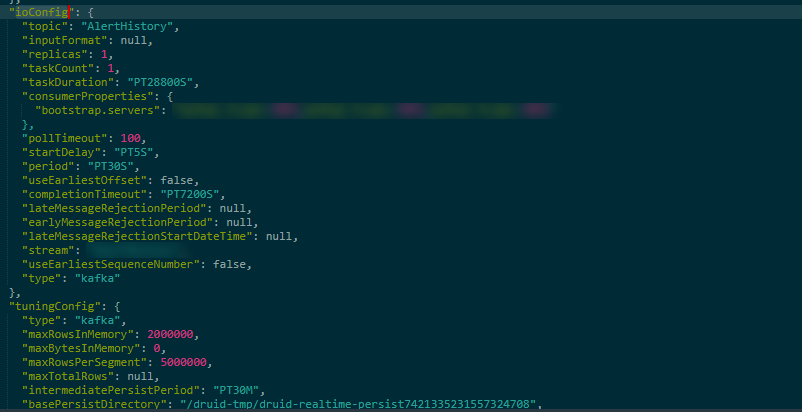
在 Supervisor 中可用的 Kafka 配置表如下: 字段(Field) 描述(Description) 是否必须(Required) type supervisor 的类型,总是 kafka 字符串。 Y dataSchema Kafka 索引服务在对数据进行导入的时候使用的数据 schema。请参考 dataSchema 页面来了解更多信息 Y ioConfig 一个 KafkaSupervisorIOConfig 对象。在这个对象中我们对 supervisor 和 索引任务(indexing task)使用 Kafka 的连接参数进行定义;对 I/O-related 进行相关设置。请参考本页面下半部分 KafkaSupervisorIOConfig 的内容。 Y tuningConfig 一个 KafkaSupervisorTuningConfig 对象。在这个配置对象中,我们对 supervisor 和 索引任务(indexing task)的性能进行设置。请参考本页面下半部分 KafkaSupervisorTuningConfig 的内容。 N 主要是用于对 Kafka 的消息的一些基本配置进行描述。 上图显示了一个配置的信息情况。 https://www.ossez.com/t/druid-kafka-supervisor/13664
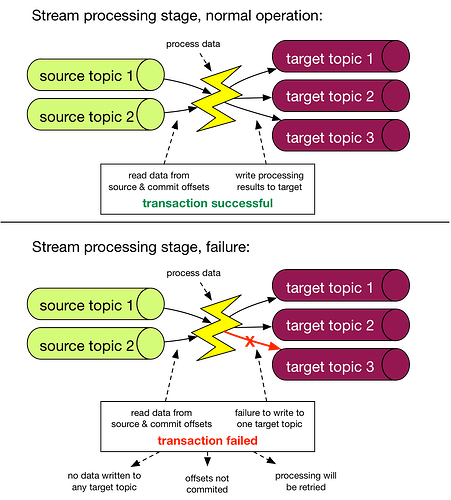
Druid 的 Kafka 索引服务(Kafka indexing service)将会在 Overlord 上启动并配置 supervisors, supervisors 通过管理 Kafka 索引任务的创建和销毁的生命周期以便于从 Kafka 中载入数据。 这些索引任务使用Kafka自己的分区和偏移机制读取事件,因此能够保证只读取一次(exactly-once)。 supervisor 对索引任务的状态进行监控,以便于对任务进行扩展或切换,故障管理等操作。 这个服务是由 druid-kafka-indexing-service 这个 druid 核心扩展(详情请见 扩展列表提供的。 Kafka索引服务支持在 Kafka 0.11.x 中开始使用的事务主题。这些更改使 Druid 使用的 Kafka 消费者与旧的 Kafka brokers 不兼容。 在使用 Druid 从 Kafka中导入数据之前,请确保你的 Kafka 版本为 0.11.x 或更高版本。 如果你使用的是旧版本的 Kafka brokers,请参阅《 Kafka升级指南 》中的内容先进行升级。 教程 针对使用 Apache Kafka 数据导入中的参考文档,请访问 Loading from Apache Kafka 页面中的教程。 exactly-once 语义 从理论上来说,Exactly-once delivery是不可能的,它的代价太高无法实际应用到生产环境,包括业内的大牛Mathias Verroaes也这么认为,它是分布式系统中最难解决的唯二问题: 但现在,我并不认为引入 Exactly-once delivery 并且支持流处理是一个真正难以解决的问题。首先,让我们来概述下消息的精确提交语义。 消息语义概述 在分布式系统中,构成系统的任何节点都是被定义为可以彼此独立失败的。比如在 Kafka中,broker可能会crash,在producer推送数据至topic的过程中也可能会遇到网络问题。根据producer处理此类故障所采取的提交策略类型,我们可以获得不同的语义: at-least-once:如果producer收到来自Kafka broker的确认(ack)或者acks = all,则表示该消息已经写入到Kafka。但如果producer ack超时或收到错误,则可能会重试发送消息,客户端会认为该消息未写入Kafka。如果broker在发送Ack之前失败,但在消息成功写入Kafka之后,此重试将导致该消息被写入两次,因此消息会被不止一次地传递给最终consumer,这种策略可能导致重复的工作和不正确的结果。 at-most-once:如果在ack超时或返回错误时producer不重试,则该消息可能最终不会写入Kafka,因此不会传递给consumer。在大多数情况下,这样做是为了避免重复的可能性,业务上必须接收数据传递可能的丢失。 exactly-once:即使producer重试发送消息,消息也会保证最多一次地传递给最终consumer。该语义是最理想的,但也难以实现,这是因为它需要消息系统本身与生产和消费消息的应用程序进行协作。例如如果在消费消息成功后,将Kafka consumer的偏移量rollback,我们将会再次从该偏移量开始接收消息。这表明消息传递系统和客户端应用程序必须配合调整才能实现excactly-once。 exactly-once 语义是在 Kafka 0.11.x 中引入的,因此 Druid 要求导入的 Kafka 版本需要在 0.11.x 以上,以便于实现 exactly-once 语义。 https://www.ossez.com/t/druid-kafka-kafka/13663

有经验的面试人员对你是不是背的答案一问便知。 学习的过程应该是理解后用自己语言表述。 背的答案会非常机械,没有任何可扩展的地方,或者稍微变一下你就可能不知道了。 如果是理解了,哪怕不是完全正确,甚至表达和设计上面都有问题,这种情况与机械的背答案是 2 回事。 面试的人如果有经验,一问便知。 要不要背答案?回答是不应该背答案,而是阅读答案后进行理解,这个过程中必要的记忆是必须的,否则过一段时间你就忘了。 理解的好处在于大方向不跑偏,因此在面试之前还是需要对一些基本概念,数据结构,设计模式等要有所了解,才能战无不胜。 https://www.ossez.com/t/java/13662
针对这个问题的短回答就是:没有任何理由保存代码为 GBK。 将项目的文件或者数据库字符集等设计到编码的地方使用 GBK,会带来很严重的兼容性问题。 保存为 GBK 通常是历史遗留问题,尤其是老的 C/S 架构项目,代码多为 GB2312 / GBK ,在早期的 Java EJB 项目中很多也会使用 GBK。 在 GBK 之前其实有一个更早的 GB2312 编码,这个编码字符集太小,经常乱码,才有了后面的 GBK,GBK 帮助解决了不少问题。 随之 WEB 环境的快速演进,目前项目中包括数据库通常都会使用 UTF-8 编码,包括数据库驱动之间也会使用 UTF-8。 其实很简单,如果你的项目就只是中国国内用用,你的字符集绝大部分是中文和英文,GBK 也差不多够用了。 如果要使用日文,韩文,德文,你怎么办。 页面 UTF-8,数据层 GBK,这里就要涉及到转码,这个是有代价的,其实也根本也没有什么必要,全部用 UTF-8 就行了。 还有就是文件的编码,如果文件编码是 GBK,用编辑器还得为 IDE 设置特定的字符集,不是闲着没事找事嘛,直接用 UTF-8,解决所有问题。 另外操作系统曾经也是不少问题,Unix 类似的系统基本上都是 UTF-8 的配置,你写的项目部署上去就是乱码,这不是闲着蛋疼。 另外 GBK 也不是最新的字符集了,如果非要用应该要使用 GB18030 字符集,这个字符集版本更新。 拿着 GBK 不想换的,基本上是老项目多,公司也不愿意折腾去维护,自己用户群基本上没有其他语言级的需求,另外也就上面懒得换而已。 其实不仅仅是中文有这个问题,到目前还有很多英文项目还只使用 ISO 8859-1 字符集,这个字符集只能使用英文,不得不说如果选用这个字符集同样也是非常短视的行为。 都 2021 年,这个问题压根就不应该存在了,UTF-8 目前基本是项目的标配。 https://www.ossez.com/t/gbk/13661
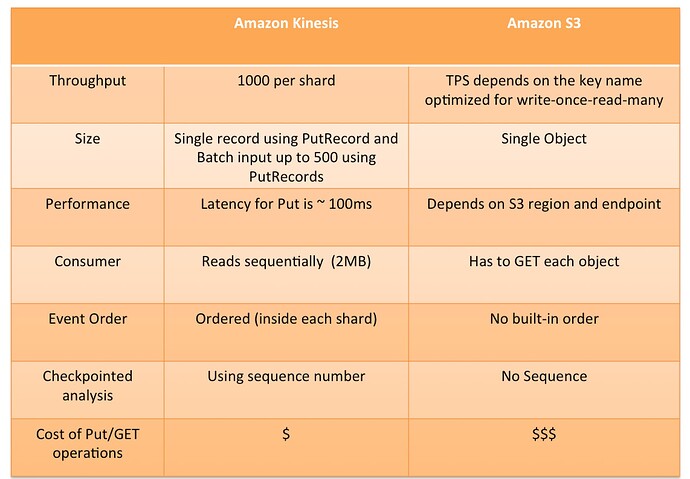
在现代大型数据环境下,消息的发送和处理就变得非常重要了。 作为消息发送处理领域里面的大象,那就是 Kafka 了。 Kafka 和 Kinesis 直接的关系 在对比 Kafka 和 Kinesis 和之前,我们需要对 Kinesis 有所了解。 什么是 Kafka Apache Kafka 是一个开源,分布式,可伸缩的发布-订阅消息系统。 负责该软件的组织是 Apache Software Foundation。 该代码是用 Scala 编写的,最初是由 LinkedIn 公司开发的。 它于2011年开源,成为 Apache 的顶级项目。 该项目旨在提供一个统一的低延迟平台,该平台能够实时处理数据馈送。 对于需要系统之间集成的不同企业基础架构,它变得越来越有价值。 希望集成的系统可以根据其需求发布或订阅特定的Kafka主题。 Kafka受事务日志的影响, Apache Kafka 背后的思想是成为可伸缩的消息队列,其结构类似于事务日志。 这个平台被指定为实时数据流。 Kafka 允许组织特定主题下的数据。 用一句话来说就是 Kafka 的消息处理能力就是快,非常的快。 什么是 Kinesis 简单来说 Kinesis 就是 AWS 的云平台的实现。 与自行部署 Kafka 来说,你不需要维护硬件平台,不需要为硬件支付费用能够非常快的进行部署。 Amazon Kinesis 可让您轻松收集、处理和分析实时流数据,以便您及时获得见解并对新信息快速做出响应。Amazon Kinesis 提供多种核心功能,可以经济高效地处理任意规模的流数据,同时具有很高的灵活性,让您可以选择最符合应用程序需求的工具。 借助 Amazon Kinesis,您可以获取视频、音频、应用程序日志和网站点击流等实时数据,也可以获取用于机器学习、分析和其他应用程序的 IoT 遥测数据。 如何选择 对有选择困难症的童鞋和公司来说也许下面的对比能够帮你做出一些决定。 主要区别 Kafka 是开源的分布式消息传递解决方案,而 Kinesis 是 Amazon提供的托管平台。 在Kafka中,您负责安装和管理集群,还负责确保高可用性,持久性和故障恢复。如果您使用的是Kinesis,则不必担心托管软件和资源。 您可以通过在本地系统中安装 Kafka 轻松学习 Kafka,而Kinesis并非如此。 Kinesis 中的定价取决于您使用的分片数量。如果您打算长时间保留邮件,则还必须支付额外的费用。 对于 Kafka,费用主要取决于您使用的 Broker 的数量。Kafka还需要一个DevOps团队进行维护,这有时成本很高。 但是,使用Kafka,只要您不耗尽存储空间,就可以将消息保留更长时间,而无需支付额外费用。 尽管 Kafka 和 Kinesis 都由生产者组成,但 Kafka 生产者将消息写入主题,而 Kinesis 生产者将数据写入 KDS。 Kinesis 还对消息的大小和消息的消耗率施加了某些限制。 Kinesis 中的最大消息大小为 1 MB,而 Kafka 消息大小可以更大。 在 Kinesis 中,您每秒可以消耗5次,每个分片最多可以消耗 2 MB,从而每秒只能写入1000条记录。 Kafka 并未施加任何隐式限制,因此费率由底层硬件决定,甚至你可以做到无限制的快速数据写入。 在安全性方面,Kafka 提供了许多客户端安全功能,例如数据加密,客户端身份验证和客户端授权,而Kinesis 通过 AWS KMS 主密钥提供服务器端加密,以加密存储在数据流中的数据。 服务器端加密的话,则很难执行客户端加密。 服务器端加密在客户端加密的基础上提供了第二层安全性。 考虑因素 看了上面那么多是不是还是有点困惑? 其实离开数据量谈方案都是耍流氓。 简单点就是 Kinesis 上手很快,如果你没有什么技术力量,在 AWS 的控制台中点一点就可以用了。 Kafka 的部署是有成本和曲线的,首先就是 Kafka 依赖 ZooKeeper 来运行,ZooKeeper 的最低运行环境都需要 3 台服务器,如果需要扩展的话那么就需要 5 台服务器,因为 ZooKeeper 为了保持高可用性,需要的是奇数台服务器的。 如果你的 ZooKeeper 部署 4 台服务器,那么 ZooKeeper 的运行效果和 3 台是一样的。 这里就导致会有使用和学习成本了。 如果你在可遇见的周期,一天就几万条消息,手上也没几个技术员,那么随便用哪个都差不多,可能用 Kinesis 还方便点,上手更快。 如果你一分钟就就万条消息的话,你还是可以考虑 Kafka 吧,因为随着消息了的增加,Kinesis 并不便宜,同时消息的保留时间是有限制的。 Kafka 的扩展是完全可以通过扩展底层硬件来实现的,同时还有维护成本在里面。 https://www.ossez.com/t/kafka-kinesis/13658
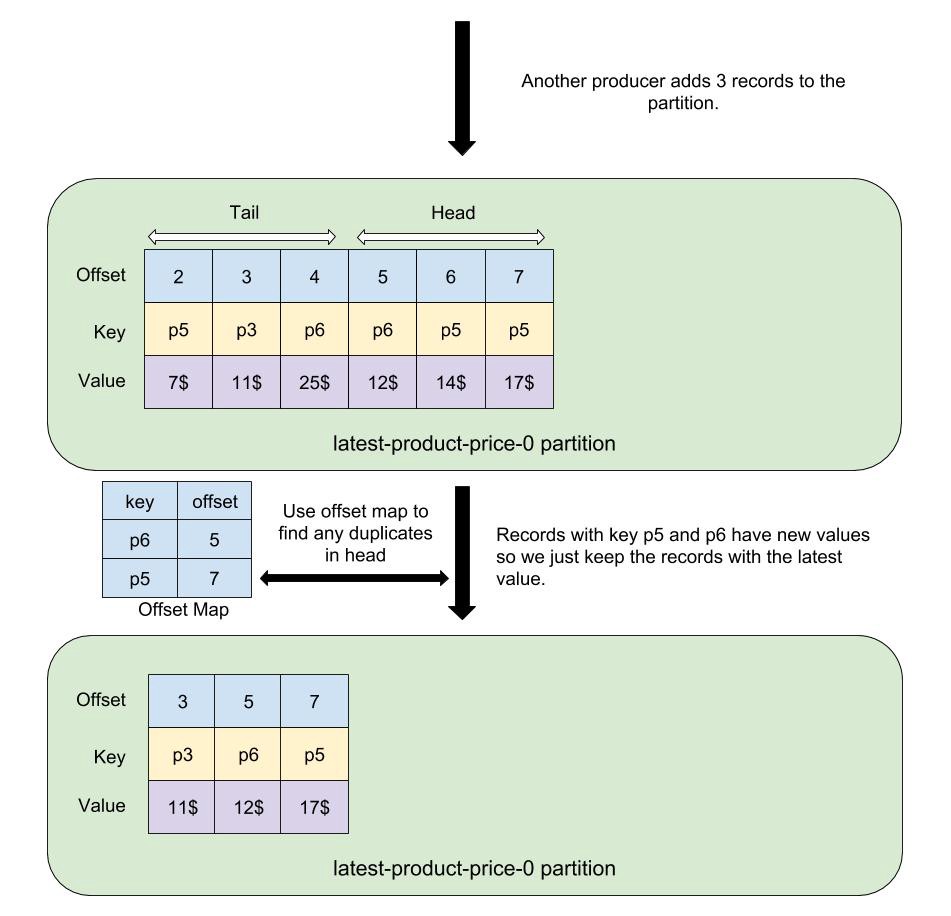
查询你的数据 当数据发送到 Kafka 后,Druid 应该能够马上查询到导入的数据的。 请访问 query tutorial 页面中的内容来了解如何针对新导入的数据运行一些查询。 清理 如果你希望其他的一些入门教程的话,你需要首先关闭 Druid 集群;删除 var 目录中的所有内容;再重新启动 Druid 集群。 这是因为本教程中其他的导入数据方式也会写入相同的 “wikipedia” 数据源,如果你使用不同的数据源的话就不需要进行清理了。 同时你可能也希望清理掉 Kafka 中的数据。你可以通过 CTRL-C 来关闭 Kafka 的进程。在关闭 Kafka 进程之前,请不要关闭 ZooKeeper 和 Druid 服务。 然后删除 Kafka 的 log 目录/tmp/kafka-logs: rm -rf /tmp/kafka-logs https://www.ossez.com/t/druid-kafka/13657#heading-1
为了能够直接启动一个服务,我们需要提交一个 supervisor 配置参数到 Druid overlord 进程中,你可以直接通过 Druid 的包运行下面的命令: curl -XPOST -H'Content-Type: application/json' -d @quickstart/tutorial/wikipedia-kafka-supervisor.json http://localhost:8081/druid/indexer/v1/supervisor 如果提交的 supervisor 被成功创建的话,在返回的结果中将会有一个创建的 supervisor ID;在我们当前的示例中,你应该可以看到返回的结果为 {"id":"wikipedia"}。 如果想了解更多有关 Kafka 的数据导入相关的信息,请参考 Druid Kafka indexing service documentation 页面中的内容。 你也可以从 Druid 的控制台中查看当前的 supervisors 和任务。针对本地服务器的访问地址为: http://localhost:8888/unified-console.html#tasks 。 https://www.ossez.com/t/druid-kafka-supervisor/13656
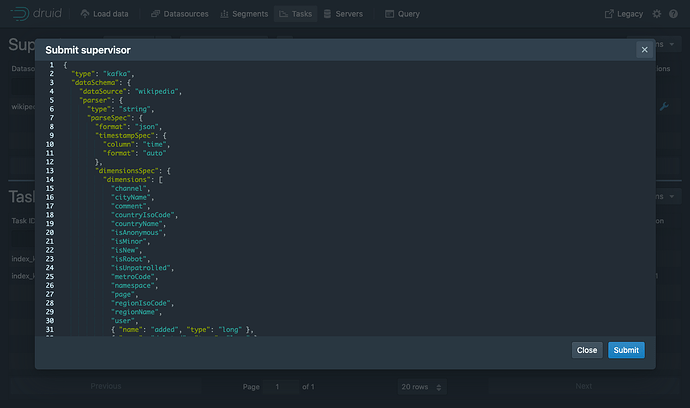
在控制台中,单击 Submit supervisor 来打开一个 supervisor 对话框。 请将下面的内容配置参数拷贝张贴到打开的对话框中,然后单击 Submit 提交。 { "type": "kafka", "spec" : { "dataSchema": { "dataSource": "wikipedia", "timestampSpec": { "column": "time", "format": "auto" }, "dimensionsSpec": { "dimensions": [ "channel", "cityName", "comment", "countryIsoCode", "countryName", "isAnonymous", "isMinor", "isNew", "isRobot", "isUnpatrolled", "metroCode", "namespace", "page", "regionIsoCode", "regionName", "user", { "name": "added", "type": "long" }, { "name": "deleted", "type": "long" }, { "name": "delta", "type": "long" } ] }, "metricsSpec" : [], "granularitySpec": { "type": "uniform", "segmentGranularity": "DAY", "queryGranularity": "NONE", "rollup": false } }, "tuningConfig": { "type": "kafka", "reportParseExceptions": false }, "ioConfig": { "topic": "wikipedia", "inputFormat": { "type": "json" }, "replicas": 2, "taskDuration": "PT10M", "completionTimeout": "PT20M", "consumerProperties": { "bootstrap.servers": "localhost:9092" } } } } 上面将会启动一个 supervisor,启动 supervisor 将会负责对任务进行管理,使用启动的任务来完成对数据的输入和从 Kafka 中获取数据。 https://www.ossez.com/t/druid-kafka-supervisor/13655
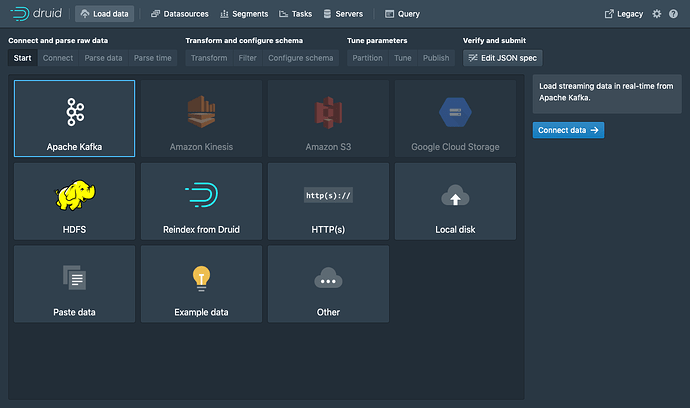
将数据载入到 Kafka 现在让我们为我们的主题运行一个生成器(producer),然后向主题中发送一些数据! 在你的 Druid 目录中,运行下面的命令: cd quickstart/tutorial gunzip -c wikiticker-2015-09-12-sampled.json.gz > wikiticker-2015-09-12-sampled.json 在你的 Kafka 的安装目录中,运行下面的命令。请将 {PATH_TO_DRUID} 替换为 Druid 的安装目录: export KAFKA_OPTS="-Dfile.encoding=UTF-8" ./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic wikipedia < {PATH_TO_DRUID}/quickstart/tutorial/wikiticker-2015-09-12-sampled.json 上面的控制台命令将会把示例消息载入到 Kafka 的 wikipedia 主题。 现在我们将会使用 Druid 的 Kafka 索引服务(indexing service)来将我们加载到 Kafka 中的消息导入到 Druid 中。 使用数据加载器(data loader)来加载数据 在 URL 中导航到 localhost:8888 页面,然后在控制台的顶部单击Load data。 选择 Apache Kafka 然后单击 Connect data。 输入 Kafka 的服务器地址为 localhost:9092 然后选择 wikipedia 为主题。 然后单击 Apply。请确定你在界面中看到的数据只正确的。 一旦数据被载入后,你可以单击按钮 “Next: Parse data” 来进行下一步的操作。 Druid 的数据加载器将会为需要加载的数据确定正确的处理器。 在本用例中,我们成功的确定了需要处理的数据格式为 json 格式。 你可以在本页面中选择不同的数据处理器,通过选择不同的数据处理器,能够帮你更好的了解 Druid 是如何帮助你处理数据的。 当 json 格式的数据处理器被选择后,单击 Next: Parse time 来进行入下一个界面,在这个界面中你需要确定 timestamp 主键字段的的列。 Druid 要求所有数据必须有一个 timestamp 的主键字段(这个主键字段被定义和存储在 __time)中。 如果你需要导入的数据没有时间字段的话,那么请选择 Constant value。 在我们现在的示例中,数据载入器确定 time 字段是唯一可以被用来作为数据时间字段的数据。 单击 Next: ... 2 次,来跳过 Transform 和 Filter 步骤。 针对本教程来说,你并不需要对导入时间进行换行,所以你不需要调整 转换(Transform) 和 过滤器(Filter) 的配置。 配置摘要(schema) 是你对 dimensions 和 metrics 在导入数据的时候配置的地方。 这个界面显示的是当我们对数据在 Druid 中进行导入的时候,数据是如何在 Druid 中进行存储和表现的。 因为我们提交的数据集非常小,因此我们可以关闭 回滚(rollup) ,Rollup 的开关将不会在这个时候显示来供你选择。 如果你对当前的配置满意的话,单击 Next 来进入 Partition 步骤。在这个步骤中你可以定义数据是如何在段中进行分区的。 在这一步中,你可以调整你的数据是如何在段中进行分配的。 因为当前的数据集是一个非常小的数据库,我们在这一步不需要进行调制。 单击 Next: Tune 来进入性能配置页面。 Tune 这一步中一个 非常重要 的参数是 Use earliest offset 设置为 True。 因为我们希望从流的开始来读取数据。 针对其他的配置,我们不需要进行修改,单击 Next: Publish 来进入 Publish 步骤。 让我们将数据源命名为 wikipedia-kafka。 最后,单击 Next 来查看你的配置。 等到这一步的时候,你就可以看到如何使用数据导入来创建一个数据导入规范。 你可以随意的通过页面中的导航返回到前面的页面中对配置进行调整。 简单来说你可以对特性目录进行编辑,来查看编辑后的配置是如何对前面的步骤产生影响的。 当你对所有的配置都满意并且觉得没有问题的时候,单击 提交(Submit). 现在你需要到界面下半部分的任务视图(task view)中来查看通过 supervisor 创建的任务。 任务视图(task view)是被设置为自动刷新的,请等候 supervisor 来运行一个任务。 当一个任务启动运行后,这个任务将会对数据进行处理后导入到 Druid 中。 在页面的顶部,请导航到 Datasources 视图。 当 wikipedia-kafka 数据源成功显示,这个数据源中的数据就可以进行查询了。 请注意: 如果数据源在经过一段时间的等待后还是没有数据的话,那么很有可能是你的 supervisor 没有设置从 Kafka 的开头读取流数据(Tune 步骤中的配置)。 在数据源完成所有的数据导入后,你可以进入 Query 视图,来针对导入的数据源来运行 SQL 查询。 因为我们当前导入的数据库很小,你可以直接运行SELECT * FROM "wikipedia-kafka" 查询来查看数据导入的结果。 请访问 query tutorial 页面中的内容来了解如何针对一个新载入的数据如何运行查询。 https://www.ossez.com/t/druid-kafka-kafka/13654