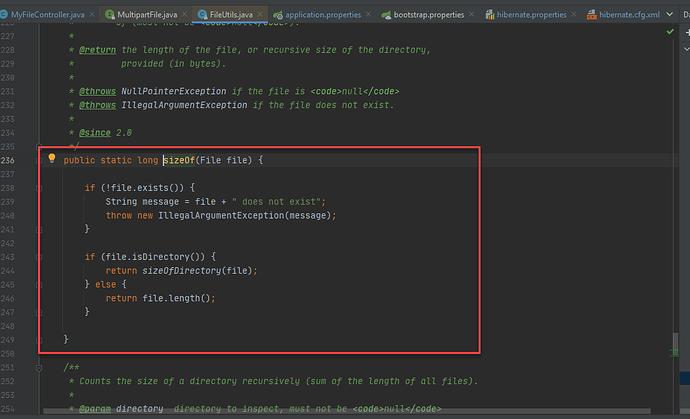
有时候我们需要知道一个文件的大小。 我们可以使用一些方法,比如说将文件读取成 InputStream,然后再使用 available() 获得长度就可以了。 我们也可以使用 FileUtils 来获得。 使用的方法是: FileUtils.sizeOf(localFileCache) localFileCache 中定义的是文件对象。 关于 sizeOf 的使用为:返回指定的文件或者文件夹的大小。如果你的 File 对象为一个文件的话,这个方法将会返回文件的大小。 如果你的 File 对象为一个目录的话,那么上面的方法将会返回这个文件夹的大小。这个文件夹的大小将会包含这个文件夹中所有子文件夹的内容。换句话说,这个方法是进行递归大小查询的。 但是,如果一个文件夹或者子文件夹有安全限制,不允许访问的话,那么这个方法将不会将上面的文件夹的内容进行计算。 https://www.ossez.com/t/java/620

当你完成安装数据库后,通常会迫不及待的进行访问和连接。但是防火墙会给你很大的麻烦,如果你不进行正确的配置的话。不管使用什么工具,可能就是一直连不上。 本文主要帮助你解决这个小问题。 下面的配置需要在 MariaDB 数据库服务器上进行配置。 我们的场景是,假设我们有一个 Web 服务器是部署在 IP 地址 192.168.0.1 上面。我们需要这个 Web 服务器能访问我们的数据库。数据库使用的端口是 3306。 在正常安装情况下,如果你的 firewalld 启动的话,Web 服务器是没有办法进行访问的,因为你的端口和 IP 地址已经被禁止了。 解决办法 可以按照下面的办法进行配置。 在配置之前,我们的流程是配置一个 zone,然后为zone 里面添加 IP 地址和端口,然后重新启动防火墙。 添加 Zone 假设我们需要为我们的 MariaDB 数据库添加一个叫 mariadb_access 的 zone 依次执行下面的命令: # firewall-cmd --new-zone=mariadb_access --permanent # firewall-cmd --reload # firewall-cmd --get-zones 上面的命令执行的是,添加一个叫 mariadb_access 的 zone,将防火墙的配置重新载入,使配置生效,然后检查添加的 zone 是否成功。 如果一切顺利的话,你应该能够看到上面的内容,表示你添加的 zone 成功了。 添加 IP 地址和端口 需要依次执行下面的命令: firewall-cmd --zone=mariadb_access --add-source=192.168.0.1 --permanent firewall-cmd --zone=mariadb_access --add-port=3306/tcp --permanent firewall-cmd --reload 上面命令执行的是,将 IP 地址添加到信任的 zone 中,将端口也添加到信任的 zone 中。 重新载入防火墙,使配置生效。 查看 zone 的配置 使用下面的命令来查看 zone 的配置,确保你的配置生效 firewall-cmd --zone=mariadb_access --list-all 在上面的命令中,你应该可以看到添加的 IP 地址和端口。 使用一条命令 上面的操作步骤是按照添加 Zone 然后添加其他参数的方法来执行的。 你需要分步执行几条命令。 如果你想通过一条命令来完成上面的操作,你可以使用下面的示例: firewall-cmd --permanent –zone=mariadb_access --add-rich-rule='rule family="ipv4" source address="192.168.0.1" port protocol="tcp" port="3306" accept' 请注意,你需要将你实际 Web 服务器的 IP 地址来进行替换。 https://www.ossez.com/t/firewall-cmd-mariadb/619

更新 CentOS 的时候提示 Jenkins 错误。 Total size: 198 M Is this ok [y/d/N]: y Downloading packages: warning: /var/cache/yum/x86_64/7/jenkins/packages/jenkins-2.249.2-1.1.noarch.rpm: Header V4 RSA/SHA512 Signature, key ID 45f2c3d5: NOKEY Public key for jenkins-2.249.2-1.1.noarch.rpm is not installed 解决办法 可以考虑执行下面的命令: [root@jenkins ~]# wget -O /etc/yum.repos.d/jenkins.repo http://pkg.jenkins.io/redhat-stable/jenkins.repo [root@jenkins ~]# rpm --import http://pkg.jenkins.io/redhat-stable/jenkins.io.key 执行上面的命令后,服务器控制台的输出为: [root@devops-norctx-com ~]# wget -O /etc/yum.repos.d/jenkins.repo http://pkg.jenkins.io/redhat-stable/jenkins.repo --2020-10-28 12:48:31-- http://pkg.jenkins.io/redhat-stable/jenkins.repo Resolving pkg.jenkins.io (pkg.jenkins.io)... 2a04:4e42:31::645, 199.232.38.133 Connecting to pkg.jenkins.io (pkg.jenkins.io)|2a04:4e42:31::645|:80... connected. HTTP request sent, awaiting response... 301 Moved Permanently Location: https://pkg.jenkins.io/redhat-stable/jenkins.repo [following] --2020-10-28 12:48:31-- https://pkg.jenkins.io/redhat-stable/jenkins.repo Connecting to pkg.jenkins.io (pkg.jenkins.io)|2a04:4e42:31::645|:443... connected. HTTP request sent, awaiting response... 200 OK Length: 85 Saving to: ‘/etc/yum.repos.d/jenkins.repo’ 100%[=============================>] 85 --.-K/s in 0s 2020-10-28 12:48:32 (2.79 MB/s) - ‘/etc/yum.repos.d/jenkins.repo’ saved [85/85] [root@devops-norctx-com ~]# rpm --import http://pkg.jenkins.io/redhat-stable/jenkins.io.key [root@devops-norctx-com ~]# 然后再运行更新就不会有问题了。 你的操作系统就能够进行更新了。 https://www.ossez.com/t/jenkins-2-249-2-1-1-noarch-rpm-is-not-installed/618
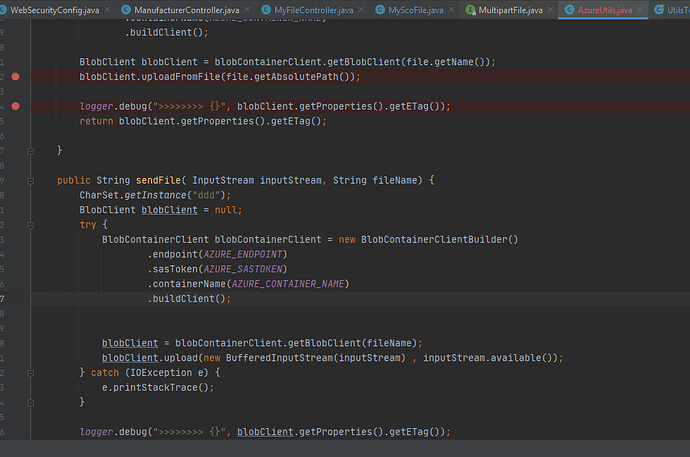
在 Azure 上传文件的时候遇到了一个下面的异常: java.io.IOException: mark/reset not supported at java.base/java.io.InputStream.reset(InputStream.java:655) at com.azure.storage.common.Utility.lambda$convertStreamToByteBuffer$4(Utility.java:236) at reactor.core.publisher.FluxDefer.subscribe(FluxDefer.java:46) at reactor.core.publisher.Mono.subscribe(Mono.java:4213) 问题解决 当给定的流不支持 mark 和 reset 就会报这个错误。 我们用的代码是: blobClient.upload(inputStream , inputStream.available()); InputStream 是不支持 mark 和 reset 的。 BufferedInputStream继承于FilterInputStream,提供缓冲输入流功能。 缓冲输入流相对于普通输入流的优势是,它提供了一个缓冲数组,每次调用read方法的时候,它首先尝试从缓冲区里读取数据,若读取失败(缓冲区无可读数据),则选择从物理数据源(例如你指定的文件)读取新数据(这里会尝试尽可能读取多的字节)放入到缓冲区中,最后再将缓冲区中的内容部分或全部返回给用户。 由于从缓冲区里读取数据远比直接从物理数据源(譬如文件)读取速度快。 Azure 使用上面的方法来尽量保障数据能够上传到存储中。 解决方案是用 BufferedInputStream 再把原来的流包装一层。 什么时候会出现这种错误呢,当你获得一个 InputStream 流,这个流是不允许读写头来回移动,也就不允许 mark/reset 机制。 所以上面的代码修改为: blobClient.upload(new BufferedInputStream(inputStream) , inputStream.available()); 然后再重试,你就会看到文件上传上去了。 登录控制台查看上传的文件。 https://www.ossez.com/t/java-io-ioexception-mark-reset-not-supported/617/2
在文件上传到服务器的时候,我们希望能够获得文件的指纹以确定文件没有被篡改过。 常用的算法最开始使用的是 MD5,随后随着技术的发展,MD5 算法已经被确定是不安全的了。 目前可能使用更多的是 HSA3_256 哈希算法。 哈希算法通常有以下几个特点: 正像快速:原始数据可以快速计算出哈希值 逆向困难:通过哈希值基本不可能推导出原始数据 输入敏感:原始数据只要有一点变动,得到的哈希值差别很大 冲突避免:很难找到不同的原始数据得到相同的哈希值 哈希算法主要有MD4、MD5、SHA。 MD4 1990年 输出128位 (已经不安全) MD5 1991年 输出128位 (已经不安全) SHA-0 1993年 输出160位 (发布之后很快就被NSA撤回,是SHA-1的前身) SHA-1 1995年 输出160位 (已经不安全) SHA-2包括SHA-224、SHA-256、SHA-384,和 SHA-512,分别输出224、256、384、512位。 (目前安全) 在 Java 中,可以使用 Apache 提供的 Apache Commons Codec,非常容易的获得文件的哈希字符串指纹。 方法也非常简单,第一步就是需要将文件读取为 InputStream。 如果自己写的话,可能这一步有点代码。 你可以使用 Apache 提供的 FileUtils.openInputStream 就可以直接将文件读取为 InputStream 了。 考察下面的代码: InputStream is = FileUtils.openInputStream(new File(SCOConstants.PATH_DATA_EXCHANGE + "Estimated vs Original Manual (JIRA) 10-23-20.csv")); MD5 哈希 在文件读取后,你只需要使用 Apache Commons Codec 提供的 DigestUtils 方法就可以了。 /** * Test to get file's MD5 Hash * * @throws Exception */ @Test public void fileMD5Test() throws Exception { String md5 = StringUtils.EMPTY; try { InputStream is = FileUtils.openInputStream(new File(SCOConstants.PATH_DATA_EXCHANGE + "Estimated vs Original Manual (JIRA) 10-23-20.csv")); md5 = DigestUtils.md5Hex(is); } catch (Exception e) { e.printStackTrace(); } logger.debug("MD5 for File: {}", md5); } 上面的代码就可以直接获得 InputStream 的 MD5 哈希。 程序的输出为: 09:32:31.522 [main] DEBUG c.i.s.c.t.utilities.CodecUtilsTest - MD5 for File: 1ec6473fc1bd50a982767f555734af64 SHA3 256 与 MD5 哈希算法是一致的。 你需要首先也将文件读取为 InputStream ,然后使用 Apache 提供的 DigestUtils.sha3_256Hex(is); 就可以了。 考察下面的代码: /** * Test to get file's SHA3_256Hex Hash * * @throws Exception */ @Test public void fileSHA3_256HexTest() throws Exception { String sha3Hex256 = StringUtils.EMPTY; try { InputStream is = FileUtils.openInputStream(new File(SCOConstants.PATH_DATA_EXCHANGE + "Estimated vs Original Manual (JIRA) 10-23-20.csv")); sha3Hex256 = DigestUtils.sha3_256Hex(is); } catch (Exception e) { e.printStackTrace(); } logger.debug("SHA3_256Hex for File: {}", sha3Hex256); } 运行程序的输出为: 09:35:48.093 [main] DEBUG c.i.s.c.t.utilities.CodecUtilsTest - SHA3_256Hex for File: https://www.ossez.com/t/java/615
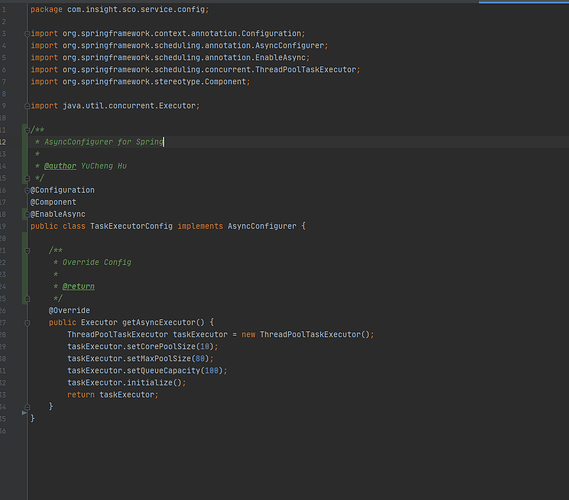
这个错误其实是 debug 级别的错误,是不影响运行的。 错误栈为: 020-10-26 15:27:57.726 DEBUG 12844 --- [nio-8080-exec-1] .s.a.AnnotationAsyncExecutionInterceptor : Could not find unique TaskExecutor bean org.springframework.beans.factory.NoUniqueBeanDefinitionException: No qualifying bean of type 'org.springframework.core.task.TaskExecutor' available: expected single matching bean but found 2: applicationTaskExecutor,taskScheduler at org.springframework.beans.factory.support.DefaultListableBeanFactory.resolveNamedBean(DefaultListableBeanFactory.java:1200) at org.springframework.beans.factory.support.DefaultListableBeanFactory.resolveBean(DefaultListableBeanFactory.java:420) at org.springframework.beans.factory.support.DefaultListableBeanFactory.getBean(DefaultListableBeanFactory.java:350) at org.springframework.beans.factory.support.DefaultListableBeanFactory.getBean(DefaultListableBeanFactory.java:343) at org.springframework.aop.interceptor.AsyncExecutionAspectSupport.getDefaultExecutor(AsyncExecutionAspectSupport.java:233) at org.springframework.aop.interceptor.AsyncExecutionInterceptor.getDefaultExecutor(AsyncExecutionInterceptor.java:157) at org.springframework.aop.interceptor.AsyncExecutionAspectSupport.lambda$configure$2(AsyncExecutionAspectSupport.java:119) 原因和解决 简单来说就是在你的 @Configuration 中必须要实现一个 AsyncConfigurer 来为 @Async 指定一个 TaskExecutor 执行的方法。 package com.insight.sco.service.config; import org.springframework.context.annotation.Configuration; import org.springframework.scheduling.annotation.AsyncConfigurer; import org.springframework.scheduling.annotation.EnableAsync; import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor; import org.springframework.stereotype.Component; import java.util.concurrent.Executor; /** * AsyncConfigurer for Spring * * @author YuCheng Hu */ @Configuration @Component @EnableAsync public class TaskExecutorConfig implements AsyncConfigurer{ /** * Override Config * * @return */ @Override public Executor getAsyncExecutor(){ ThreadPoolTaskExecutor taskExecutor = new ThreadPoolTaskExecutor(); taskExecutor.setCorePoolSize(10); taskExecutor.setMaxPoolSize(80); taskExecutor.setQueueCapacity(100); taskExecutor.initialize(); return taskExecutor; } } 可以将上面的方法拷贝放到你 Spring 的项目中,这样你的 Spring 项目就可以告诉应用的上下文使用哪一个异步方法。 https://www.ossez.com/t/spring-could-not-find-unique-taskexecutor-bean/614
要登录你的小商店,前提是你的小商店已经开店成功了。 在开店成功后,你可用有下面 2 个登录路径: 小商店网页 你可以通过小商店的专有网页地址进行登录。 访问下面的地址:https://shop.weixin.qq.com/ 扫码后登录即可。 微信公众平台 你也可以通过微信公众平台进行登录。 登录访问的地址为:https://mp.weixin.qq.com/ 访问上面的微信公众平台后,用你已经注册的小程序微信号登录即可。 微信公众平台登录界面。 https://www.ossez.com/t/topic/613
可能是微信小商店很多时候还在内测阶段。 登录路径也不是非常明显,包括如何注册也是信息是否混乱。 经过一整折腾,后来发现其实有 2 个路径可以去做。 微信直接开店 在登录微信后,直接搜索小程序【小商店助手】 点进去就可以看到需要的界面了。如果你需要开店的话,你需要你的身份证号码等信息。 注册成功后就可以直接开店了。 通过网页 相信这个是很多人希望找到的链接了。 小商店的链接地址为:https://shop.weixin.qq.com/ 不管你有没有注册过,你可以用你的微信号直接扫码。 如果你已经开店成功了,网页界面会让你登录,然后进行相关的设置和分类等。 分类的设置是必须在网页中做的。 如果还没有设置过开店的话,会提示你在手机上设置开店。 与开始你在手机上搜索小商店助手开店的界面是一样的。 https://www.ossez.com/t/topic/612
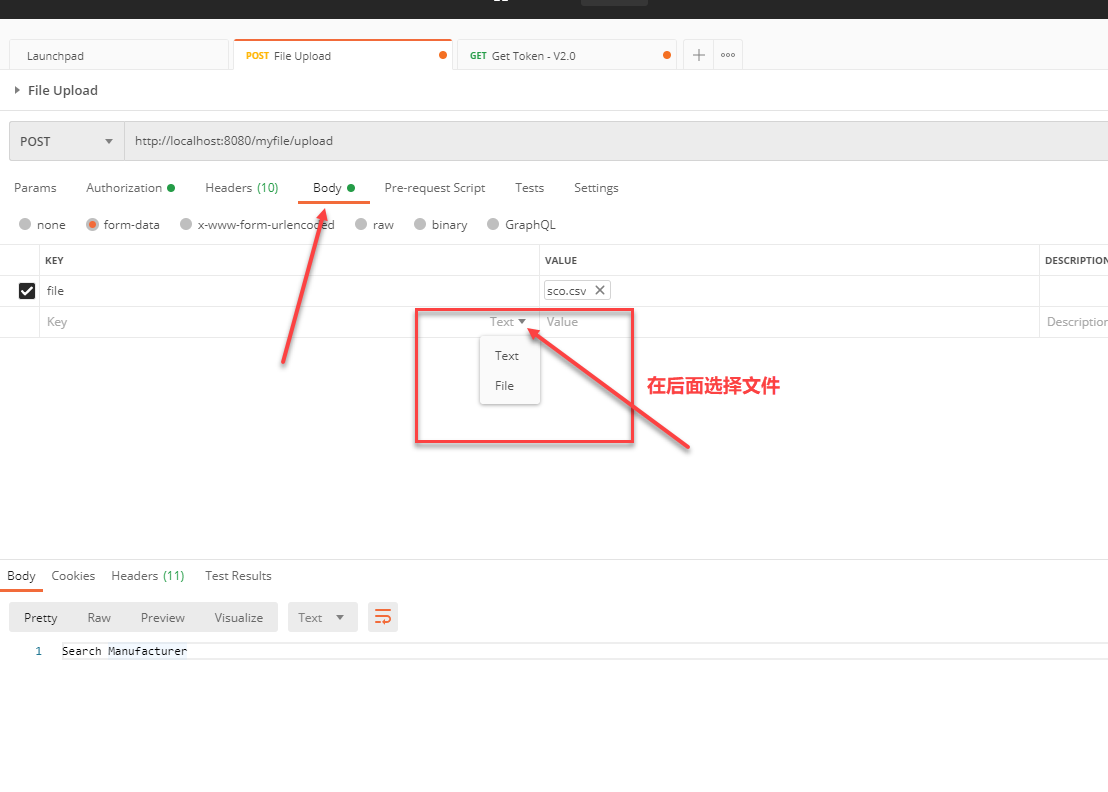
很多时候我们都会用 Postman 来测试 API。 在最开始的时候,我们都会使用字符串呀什么的来进行测试,随着 API 的继续开发,我们希望通过 API 来上传文件。 如何在 Postman 中进行设置来上传文件? 设置方法 Postman 已经帮我们想到了。 在进入 Postman 以后,找到你需要进行测试的 API,然后选择 body。 在 Body 下面选择文件,然后输入 key 就可以了。 其实主要开始很多人不知道怎么设置的原因是,你需要将鼠标移动到后面,然后在下拉框中选择文件。 key,输入你的名字,一般来说我们都会选择 file,这个需要和后台 API 的进行匹配的。 https://www.ossez.com/t/postman-api/610
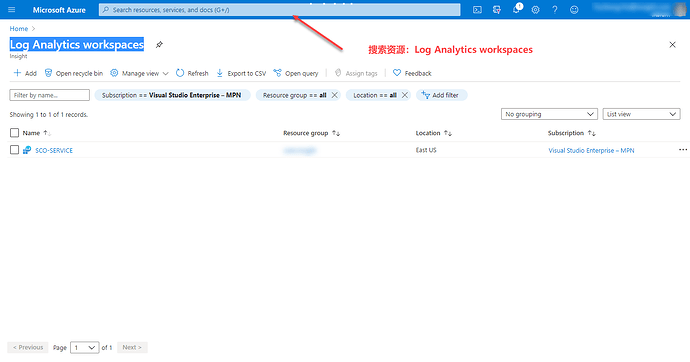
Azure 提供了一个 Application Insights 工具。 这个工具可以对 Spring Boot 项目中的 API 请求,日志进行分析。 你需要做的就是在你的 Spring Boot 项目中配置好依赖和参数后,Spring Boot 项目启动后就会自动将日志上传到 Azure 供分析。 配置 Azure 不管怎么用,Azure 都首先需要进行配置。 我们现在针对配置的是日志删除到 Azure 上进行日志分析。 Log Analytics workspaces 我们首先需要配置一个 Log Analytics workspaces,搜索资源 Log Analytics workspaces。 在弹出的界面中将会显示已经配置好的日志分析工作空间。 如果你还没有的话,你需要创建一个。 单击界面上的 Add 按钮,进行新建。 在新建的对话框中你需要对你的费用订购部分进行配置。 如果你还没有配置的话,你可能需要到 Azure 的控制台中配置信用卡。 在第二部分输入的是名称和区域,名称可以根据需要命名,区域的话,选一个离你最近的就可以了。 在配置完上面的参数后,创建就可以了。 Application Insights 在最上面的搜索框中搜索 Application Insights 然后你会看到 Application Insights 的界面,单击左侧的添加按钮来添加一个应用。 这里也有几个配置,在最上面的是费用计算和订购。 中间的部分是有关资源的名称。 在最下面的就是有关日志的配置了,因为要在这里进行选择,这就是为什么我们需要首先配置日志工作空间的原因,否则是没有办法配置日志的。 在一切配置妥当后,单击最下面的预览并创建即可。 在创建成功后,你的项目会获得一个 Instrumentation Key,这个是需要配置到你 Spring Boot 项目中的。 现在你可以先拷贝下来。 Spring 项目 在Spring 项目中需要进行一些调整就可以了。 maven 依赖 你需要为你的项目添加 Maven 依赖。 <dependency> <groupId>com.microsoft.azure</groupId> <artifactId>applicationinsights-logging-logback</artifactId> <version>2.6.2</version> </dependency> 上面的依赖将会将日志上传需要的类添加进来。 application.properties 在 Spring Boot 配置文件中,添加下面的参数 # Azure Application Insights azure.application-insights.instrumentation-key=[开始让你拷贝的 ID] spring.application.name=[Azure 中定义的名称] 根据上面在 Azure 的配置,将上面的参数修改为你的 Azure 配置。 logback.xml 因为我们的项目使用的是 logback 为日志,因此我们需要在 logback.xml 中添加下面的内容。 <appender name="aiAppender" class="com.microsoft.applicationinsights.logback.ApplicationInsightsAppender"> <instrumentationKey>[开始让你拷贝的 ID]</instrumentationKey> </appender> <!-- APPENDER-REF --> <root level="debug"> <appender-ref ref="aiAppender"/> </root> 上面的内容非常简单,就是将日志级别为 debug 的全部输出到 Azure 上面去。 在官方的代码中,这里使用了日志级别为 TRACE,我们不建议使用。因为这样会输出非常多的日志,让你的访问非常缓慢。 查看结果 当所有配置完成以后,开始在你的本地运行你的 Spring Boot 应用程序。 稍等一些时间后登录 Azure,然后选择 Transaction search。 在界面中你可能看不到任何数据,你需要单击界面中的显示所有 24 小时内的数据。 如果你能看到程序删除的日志,主要是查看时间,那么就说明一切都已经配置好了。 https://www.ossez.com/t/spring-boot-azure-application-insights/609